ImagePullJob
Note: v1beta1 available from Kruise v1.9.0
NodeImage and ImagePullJob are new CRDs provided since Kruise v0.8.0 version.
Kruise will create a NodeImage for each Node, and it contains images that should be downloaded on this Node.
Users can create an ImagePullJob to declare an image should be downloaded on which nodes.
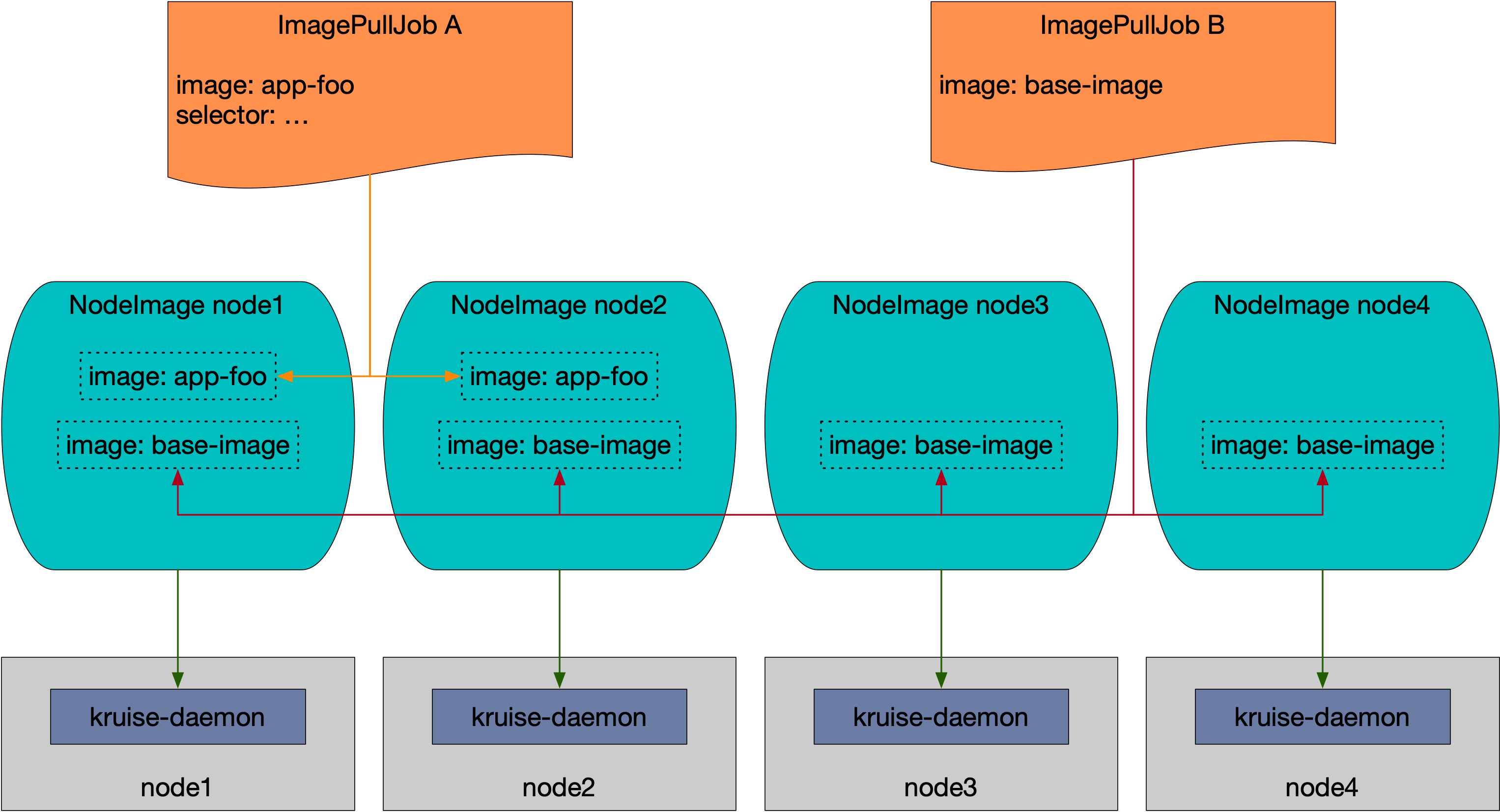
Note that the NodeImage is quite a low-level API. You should only use it when you prepare to pull an image on a definite Node. Otherwise, you should use the ImagePullJob to pull an image on a batch of Nodes.
Feature-gate
Since kruise v1.5.0 ImagePullJob/ImageListPullJob feature is turned off by default to reduce the privilege of default installation. One can turn it on by setting feature-gate ImagePullJobGate.
$ helm install/upgrade kruise https://... --set featureGates="ImagePullJobGate=true"
ImagePullJob (high-level)
ImagePullJob is a namespaced-scope resource.
API definition: https://github.com/openkruise/kruise/blob/master/apis/apps/v1beta1/imagepulljob_types.go
- v1beta1
- v1alpha1
apiVersion: apps.kruise.io/v1beta1
kind: ImagePullJob
metadata:
name: job-with-always
spec:
image: nginx:1.9.1 # [required] image to pull
parallelism: 10 # [optional] the maximal number of Nodes that pull this image at the same time, defaults to 1
selector: # [optional] the names or label selector to assign Nodes (only one of them can be set)
names:
- node-1
- node-2
matchLabels:
node-type: xxx
# podSelector: # [optional] label selector over pods that should pull image on nodes of these pods. Mutually exclusive with selector.
# matchLabels:
# pod-label: xxx
# matchExpressions:
# - key: pod-label
# operator: In
# values:
# - xxx
completionPolicy:
type: Always # [optional] defaults to Always
activeDeadlineSeconds: 1200 # [optional] no default, only work for Always type
ttlSecondsAfterFinished: 300 # [optional] no default, only work for Always type
pullPolicy: # [optional] defaults to backoffLimit=3, timeoutSeconds=600
backoffLimit: 3
timeoutSeconds: 300
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
metadata:
name: job-with-always
spec:
image: nginx:1.9.1 # [required] image to pull
parallelism: 10 # [optional] the maximal number of Nodes that pull this image at the same time, defaults to 1
selector: # [optional] the names or label selector to assign Nodes (only one of them can be set)
names:
- node-1
- node-2
matchLabels:
node-type: xxx
# podSelector: # [optional] label selector over pods that should pull image on nodes of these pods. Mutually exclusive with selector.
# matchLabels:
# pod-label: xxx
# matchExpressions:
# - key: pod-label
# operator: In
# values:
# - xxx
completionPolicy:
type: Always # [optional] defaults to Always
activeDeadlineSeconds: 1200 # [optional] no default, only work for Always type
ttlSecondsAfterFinished: 300 # [optional] no default, only work for Always type
pullPolicy: # [optional] defaults to backoffLimit=3, timeoutSeconds=600
backoffLimit: 3
timeoutSeconds: 300
You can write the names or label selector in the selector field to assign Nodes (only one of them can be set).
If no selector is set, the image will be pulled on all Nodes in the cluster.
Or you can write the podSelector to pull image on nodes of these pods. podSelector is mutually exclusive with selector.
Also, ImagePullJob has two completionPolicy types:
Alwaysmeans this job will eventually complete with either failed or succeeded.activeDeadlineSeconds: timeout duration for this jobttlSecondsAfterFinished: after this job finished (including success or failure) over this time, this job will be removed
Nevermeans this job will never complete, it will continuously pull image on the desired Nodes every day.
FEATURE STATE: Kruise v1.9.0
We can also use AdvancedCronjob to schedule ImageListPullJob now. With this feature, user can preheat their large images for the pods using by AI/ML jobs.
Configure secrets
If the image is in a private registry, you may want to configure the pull secrets for the image:
# ...
spec:
pullSecrets:
- secret-name1
- secret-name2
Because of ImagePullJob is a namespaced-scope resource, the secrets should be in the same namespace of this ImagePullJob,
and you should only put the secret names into pullSecrets field.
You can also use Configure image credential provider for private registry.
Configure image credential provider
FEATURE STATE: Kruise v1.7.0
Starting from Kubernetes v1.20, the kubelet can dynamically retrieve credentials for a container image registry using exec plugins. Refer Community Documentation.
OpenKruise also supports the same way for pre-download image with the following steps:
a. Configure image credential provider on AWS:
- Install AWS's credential provisioning plugin on k8s nodes.
- Create credential-provider-config Configmap in K8S:
apiVersion: v1
kind: ConfigMap
metadata:
name: credential-provider-config
namespace: kruise-system
data:
CredentialProviderPlugin.yaml: |
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
providers:
# name is the required name of the credential provider.
- name: ecr-credential-provider
matchImages:
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
defaultCacheDuration: "12h"
apiVersion: credentialprovider.kubelet.k8s.io/v1
env:
- name: AWS_PROFILE
value: temp
- Install kruise with AWS Shared Credentials File.
If you have a shared credentials file($HOME/.aws/credentials) on every machine, you can mount the directory to kruise-daemon for authentication, as follows:
helm install kruise https://... --set installation.createNamespace=false --set daemon.credentialProvider.enable=true --set daemon.credentialProvider.hostPath=/etc/eks/image-credential-provider --set daemon.credentialProvider.configmap=credential-provider-config --set daemon.credentialProvider.awsCredentialsDir=/root/.aws
- Create an ImagePullJob, authenticate the image repository via the above plugin, and complete pre-download image.
Note: If other cloud vendors (e.g., Tencent Cloud) have a similar mechanism, it should work. If you have similar needs, please contact us.
Attach metadata into cri interface
FEATURE STATE: Kruise v1.4.0
When kubelet creates pods, kubelet will attach pod metadata as podSandboxConfig params in the PullImage CRI interface. The OpenKruise ImagePullJob also supports the similar capability, as follows:
- v1beta1
- v1alpha1
apiVersion: apps.kruise.io/v1beta1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
sandboxConfig:
annotations:
io.kubernetes.image.metrics.tags: "cluster=cn-shanghai"
labels:
io.kubernetes.image.app: "foo"
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
sandboxConfig:
annotations:
io.kubernetes.image.metrics.tags: "cluster=cn-shanghai"
labels:
io.kubernetes.image.app: "foo"
Image Pull Policy support 'Always'
FEATURE STATE: Kruise v1.6.0
- spec.imagePullPolicy=Always means that kruise always attempts to pull the latest image, even if with the name as previous one.
- spec.imagePullPolicy=IfNotPresent means that kruise only pull the image if it isn't present on node.
- Defaults is IfNotPresent.
- v1beta1
- v1alpha1
apiVersion: apps.kruise.io/v1beta1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
imagePullPolicy: Always | IfNotPresent
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
imagePullPolicy: Always | IfNotPresent
Node-side concurrency control
FEATURE STATE: Kruise v1.9.0
Since v1.9.0, the kruise-daemon supports node-side concurrency control for image pulling. This feature limits the number of concurrent image pulls on each node, preventing resource exhaustion (CPU, memory, disk I/O) when multiple ImagePullJobs target the same node simultaneously.
The concurrency limit can be configured via the --max-concurrency flag of kruise-daemon. By default, the daemon uses a worker pool to limit concurrent image pull operations per node.
ImageListPullJob
FEATURE STATE: Kruise v1.5.0
ImagePullJob can only support a single image pre-download, one can use multiple ImagePullJob to download multiple images, or use ImageListPullJob to pre-download multiple images in a single job, as follows:
- v1beta1
- v1alpha1
apiVersion: apps.kruise.io/v1beta1
kind: ImageListPullJob
metadata:
name: job-with-always
spec:
images:
- nginx:1.9.1 # [required] image to pull
- busybox:1.29.2
parallelism: 10 # [optional] the maximal number of Nodes that pull this image at the same time, defaults to 1
selector: # [optional] the names or label selector to assign Nodes (only one of them can be set)
names:
- node-1
- node-2
matchLabels:
node-type: xxx
completionPolicy:
type: Always # [optional] defaults to Always
activeDeadlineSeconds: 1200 # [optional] no default, only work for Always type
ttlSecondsAfterFinished: 300 # [optional] no default, only work for Always type
pullPolicy: # [optional] defaults to backoffLimit=3, timeoutSeconds=600
backoffLimit: 3
timeoutSeconds: 300
apiVersion: apps.kruise.io/v1alpha1
kind: ImageListPullJob
metadata:
name: job-with-always
spec:
images:
- nginx:1.9.1 # [required] image to pull
- busybox:1.29.2
parallelism: 10 # [optional] the maximal number of Nodes that pull this image at the same time, defaults to 1
selector: # [optional] the names or label selector to assign Nodes (only one of them can be set)
names:
- node-1
- node-2
matchLabels:
node-type: xxx
completionPolicy:
type: Always # [optional] defaults to Always
activeDeadlineSeconds: 1200 # [optional] no default, only work for Always type
ttlSecondsAfterFinished: 300 # [optional] no default, only work for Always type
pullPolicy: # [optional] defaults to backoffLimit=3, timeoutSeconds=600
backoffLimit: 3
timeoutSeconds: 300
NodeImage (low-level)
NodeImage is a cluster-scope resource.
API definition: https://github.com/openkruise/kruise/blob/master/apis/apps/v1beta1/nodeimage_types.go
When Kruise has been installed, nodeimage-controller will create NodeImages for Nodes with the same names immediately. And when a Node has been added or removed, nodeimage-controller will also create or delete NodeImage for this Node.
What's more, nodeimage-controller will also synchronize labels from Node to NodeImage. So the NodeImage and Node always have the same name and labels. You can get NodeImage with the Node name, or list NodeImage with the Node labels as selector.
Typically, an empty NodeImage looks like this:
apiVersion: apps.kruise.io/v1alpha1
kind: NodeImage
metadata:
labels:
kubernetes.io/arch: amd64
kubernetes.io/os: linux
# ...
name: node-xxx
# ...
spec: {}
status:
desired: 0
failed: 0
pulling: 0
succeeded: 0
If you want to pull an image such as ubuntu:latest on this Node, you can:
kubectl edit nodeimage node-xxxand write below into it (ignore the comments):
# ...
spec:
images:
ubuntu: # image name
tags:
- tag: latest # image tag
pullPolicy:
ttlSecondsAfterFinished: 300 # [required] after this image pulling finished (including success or failure) over 300s, this task will be removed
timeoutSeconds: 600 # [optional] timeout duration for once pulling, defaults to 600
backoffLimit: 3 # [optional] retry times for pulling, defaults to 3
activeDeadlineSeconds: 1200 # [optional] timeout duration for this task, no default
kubectl patch nodeimage node-xxx --type=merge -p '{"spec":{"images":{"ubuntu":{"tags":[{"tag":"latest","pullPolicy":{"ttlSecondsAfterFinished":300}}]}}}}'
You can read the NodeImage status using kubectl get nodeimage node-xxx -o yaml,
and you will find the task removed from spec and status after it has finished over 300s.
FEATURE STATE: Kruise v1.9.0
If you want to change the default ttl extra seconds (300s) for Nodeimage tasks, you can specify the parameter --default-ttlseconds-for-always-nodeimage when starting kruise-controller-manager.
Notice that you can't set ttlSecondsAfterFinished in AdvancedCronJob, as this will also impact the lifecycle of ImageListPullJob. For detail, please refer to issue #2213 and #2214.
FAQ
- If ImagePullJob failed, as follows:
% kubectl get imagepulljob
NAME TOTAL ACTIVE SUCCEED FAILED AGE MESSAGE
job-with-always 4 0 0 4 9m49s job has completed
- You can find out the failed node.name from imagePullJob.status, as follows:
% kubectl get imagepulljob job-with-always -oyaml
apiVersion: apps.kruise.io/v1beta1
kind: ImagePullJob
status:
active: 0
completionTime: "2024-08-09T10:06:26Z"
desired: 4
failed: 4
failedNodes:
- cn-hangzhou.x.125
- cn-hangzhou.x.126
- cn-hangzhou.x.127
- cn-hangzhou.x.128
message: job has completed
startTime: "2024-08-09T10:03:52Z"
succeeded: 0
- You can see the exact cause of failure via NodeImage, as follows:
% kubectl get nodeimage cn-hangzhou.x.125 -oyaml
apiVersion: apps.kruise.io/v1beta1
kind: NodeImage
status:
desired: 1
failed: 1
imageStatuses:
nginx:
tags:
- completionTime: "2024-08-09T10:06:22Z"
message: 'Failed to pull image reference "nginx:1.9.1": rpc error: code =
DeadlineExceeded desc = failed to pull and unpack image "docker.io/library/nginx:1.9.1":
failed to copy: httpReadSeeker: failed open: failed to do request: Get "https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/c5/c5dd085dcc7c78a296c80b87916831fd19a3f447d94b99580ccd19a052720211/data?verify=1723200943-x6RCoD1a2P3aEdh1%!B(MISSING)XcQSFe2h%!B(MISSING)U%!D(MISSING)":
dial tcp 10.1.1.1:443: i/o timeout'
phase: Failed
startTime: "2024-08-09T10:03:52Z"
tag: 1.9.1
pulling: 0
succeeded: 0