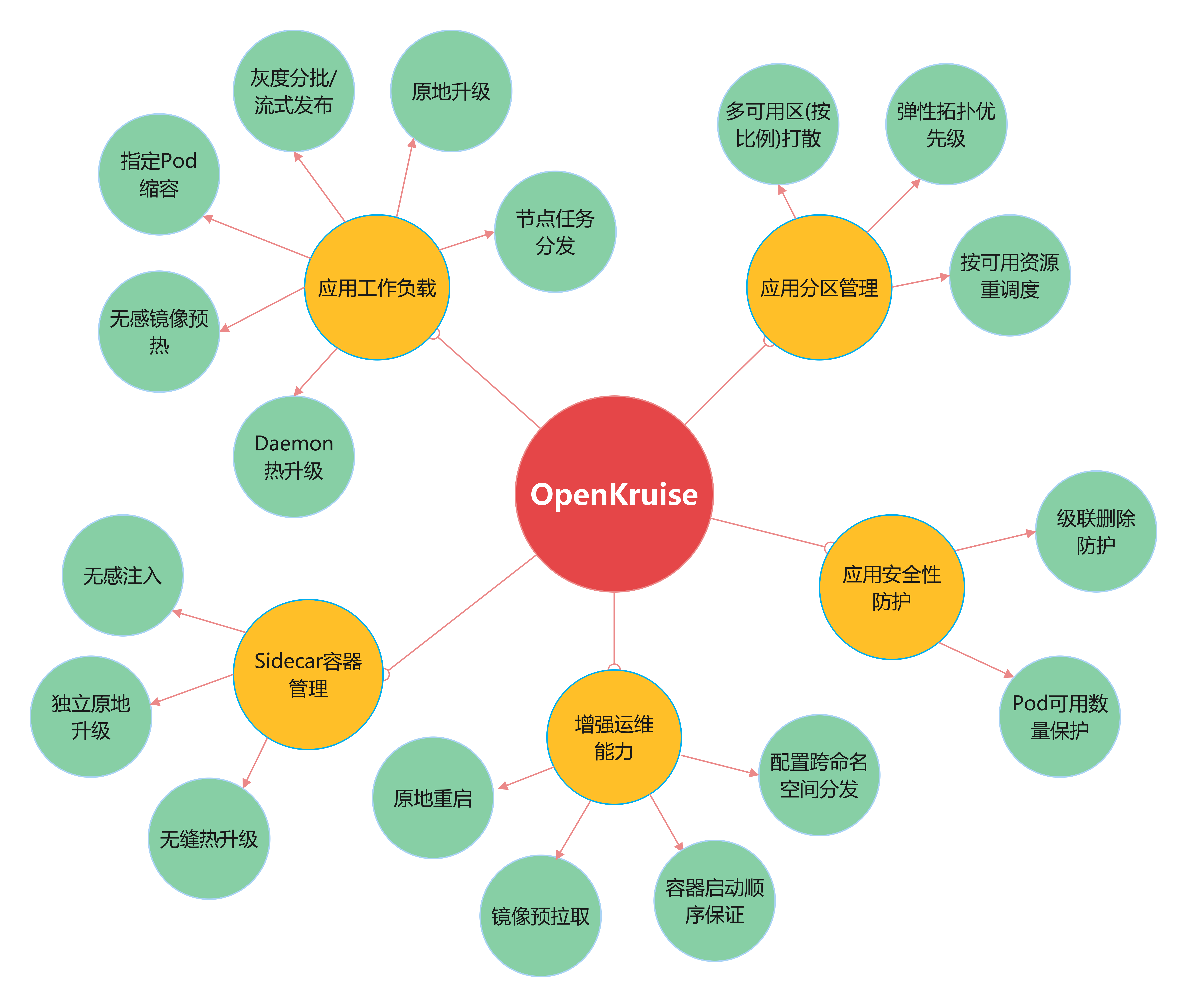
OpenKruise( https://github.com/openkruise/kruise )是阿里云开源的云原生应用自动化管理套件,也是当前托管在 Cloud Native Computing Foundation (CNCF) 下的孵化项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,是阿里内部生产环境大规模应用的基于 Kubernetes 之上的标准扩展组件,也是紧贴上游社区标准、适应互联网规模化场景的技术理念与最佳实践。
OpenKruise 在 2023.3.31 发布了最新的 v1.4 版本(ChangeLog),新增 Job Sidecar Terminator 重磅功能,本文以下对新版本做整体的概览介绍。
1. 重要更新
- 为了方便大家使用 Kruise 增强能力,默认打开了一些稳定的能力,如下:ResourcesDeletionProtection, WorkloadSpread, PodUnavailableBudgetDeleteGate, InPlaceUpdateEnvFromMetadata, StatefulSetAutoDeletePVC, PodProbeMarkerGate。上述能力大部分是需要特别配置才会生效的,所以默认打开一般不会对存量集群造成影响,如果有一些特性不想使用,可以在升级时关闭。
- Kruise-Manager leader 选举方式从 configmaps 迁移为 configmapsleases,为后面迁移到 leases 方式做准备,另外,这是官方提供的平滑升级的方式,不会对存量的集群造成影响。
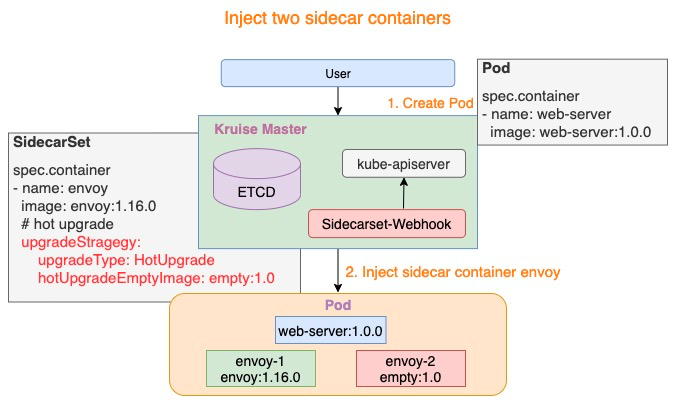
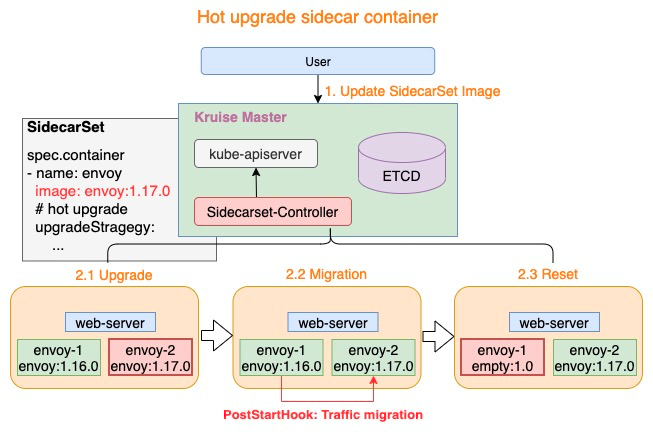
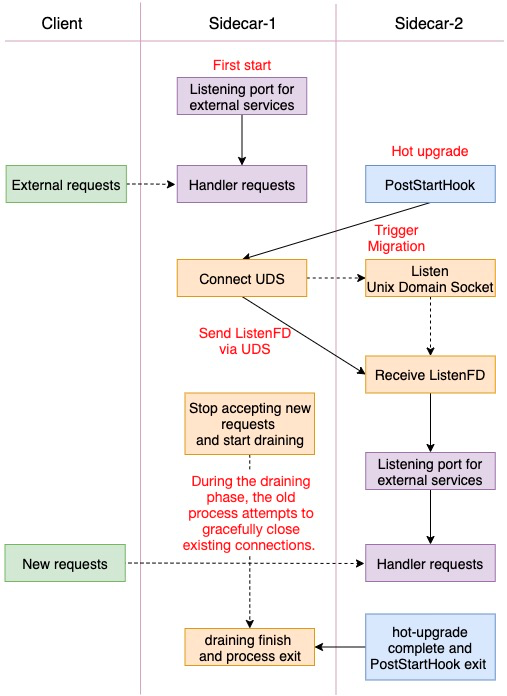
2. Sidecar容器管理能力:Job Sidecar Terminator
在 Kubernetes 中对于 Job 类型 Workload,人们通常希望当主容器完成任务并退出后,Pod 进入已完成状态。然而,当这些 Pod 拥有 Long-Running Sidecar 容器时,由于 Sidecar 容器在主容器退出后无法自行退出,导致 Pod 一直无法进入已完成状态。面对这个问题,社区的常见解决方案一般都需要对 Main 和 Sidecar 进行改造,两者通过 Volume 共享来实现 Main 容器退出之后,Sidecar 容器完成退出的效果。
社区的解决方案可以解决这个问题,但是需要对容器进行改造,尤其对于社区通用的 Sidecar 容器,改造和维护的成本太高了。
为此,我们在 Kruise 中加入了一个名为 SidecarTerminator 的控制器,专门用于在此类场景下,监听主容器的完成状态,并选择合适的时机终止掉 Pod 中的 sidecar 容器,并且无需对 Main 和 Sidecar 容器进行侵入式改造。
运行在普通节点的 Pod
对于运行于普通节点的 Pod(常规Kubelet),使用该特性非常简单,用户只需要在要在目标 sidecar 容器中添加一个特殊的 env 对其进行标识,控制器会在恰当的时机利用 Kruise Daemon 提供的 CRR 的能力,将这些 sidecar 容器终止:
kind: Job
spec:
template:
spec:
containers:
- name: sidecar
env:
- name: KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT
value: "true"
- name: main
...
运行在虚拟节点的 Pod
对于一些提供 Serverless 容器的平台,例如 ECI 或者 Fargate, 其 Pods 只能运行于 Virtual-Kubelet 之类的虚拟节点。 然而,Kruise Daemon 无法部署和工作在这些虚拟节点之上,导致无法使用 CRR 能力将容器终止。 但幸运地是,我们可以借助原生 Kubernetes 提供的 Pod 原地升级机制来达到同样的目的:只需要构造一个特殊镜像,这个镜像的唯一作用就是当被拉起后,会快速地主动退出,这样一来,只需要在退出 sidecar 时,将原本的 sidecar 镜像替换为快速退出镜像,即可达到退出 sidecar 的目的。
步骤一: 准备一个快速退出镜像
- 该镜像只需要具备非常简单的逻辑:当其被拉起后,直接退出,且退出码为 0。
- 该镜像需要兼容原 sidecar 镜像的 commands 和 args,以防容器被拉起时报错。
步骤二: 配置你的 sidecar 容器
kind: Job
spec:
template:
spec:
containers:
- name: sidecar
env:
- name: KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT_WITH_IMAGE
value: "example/quick-exit:v1.0.0"
- name: main
...
使用你自己准备的快速退出镜像来替换上述 "example/quick-exit:v1.0.0".
注意事项
- sidecar 容器必须能够响应 SIGTERM 信号,并且当收到此信号时,entrypoint 进程需要退出(即 sidecar 容器需要退出),并且退出码应当为 0。
- 该特性适用于任意 Job 类型 Workload 所管理的 Pod,只要他们的 RestartPolicy 为 Never/OnFailure 即可。
- 具有环境变量 KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT 的容器将被视为 sidecar 容器,其他容器将被视为主容器,当所有主容器完成后,sidecar 容器才会被终止:
- 在 Never 重启策略下,主容器一旦退出,将被视为"已完成"。
- 在 OnFailure 重启策略下,主容器退出代码必须为0,才会被视为"已完成"。
- 且运行在普通节点方式下,
KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT的优先级高于KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT_WITH_IMAGE
3. 增强版本的工作负载
CloneSet 优化性能 :新增 FeatureGate CloneSetEventHandlerOptimization
当前,无论是 Pod 的状态变化还是 Metadata 变化,Pod Update 事件都会触发 CloneSet reconcile 逻辑。CloneSet Reconcile 默认配置了三个 worker,对于集群规模较小的场景,这种情况并不会造成问题。
但对于集群规模较大或 Pod Update 事件较多的情况,这些无效的 reconcile 将会阻塞真正的 CloneSet reconcile,进而导致 CloneSet 的滚动升级等变更延迟。为了解决这个问题,可以打开 feature-gate CloneSetEventHandlerOptimization 来减少一些不必要的 reconcile 入队。
CloneSet 新增 disablePVCReuse 字段
如果一个 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVCs 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的 instance-id 并关联原来的 PVCs。
然而,如果 Pod 所在的 Node 出现异常,复用可能会导致新 Pod 启动失败,详情参考 issue 1099。为了解决这个问题,您可以设置字段 DisablePVCReuse=true,当 Pod 被驱逐或者删除后,与 Pod 相关的 PVCs 将被自动删除,不再被复用。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
...
replicas: 4
scaleStrategy:
disablePVCReuse: true
CloneSet 增加 PreNormal 生命周期钩子
CloneSet 已经支持了PreparingUpdate、PreparingDelete 两种生命周期钩子,用于应用的优雅下线,详情参考社区文档。为了支持优雅上线的场景,本次新增加了 PreNormal 状态,具体如下:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# define with finalizer
lifecycle:
preNormal:
finalizersHandler:
- example.io/unready-blocker
# or define with label
# lifecycle:
# preNormal:
# labelsHandler:
# example.io/block-unready: "true"
当 CloneSet 创建一个 Pod(包括正常扩容和重建升级)时:
- 如果 Pod 满足了
PreNormalhook 的定义,才会被认为是Available,并且才会进入Normal状态 这对于一些 Pod 创建时的后置检查很有用,比如你可以检查 Pod 是否已经挂载到 SLB 后端,从而避免滚动升级时,旧实例销毁后,新实例挂载失败导致的流量损失。
4. 高级的应用运维能力
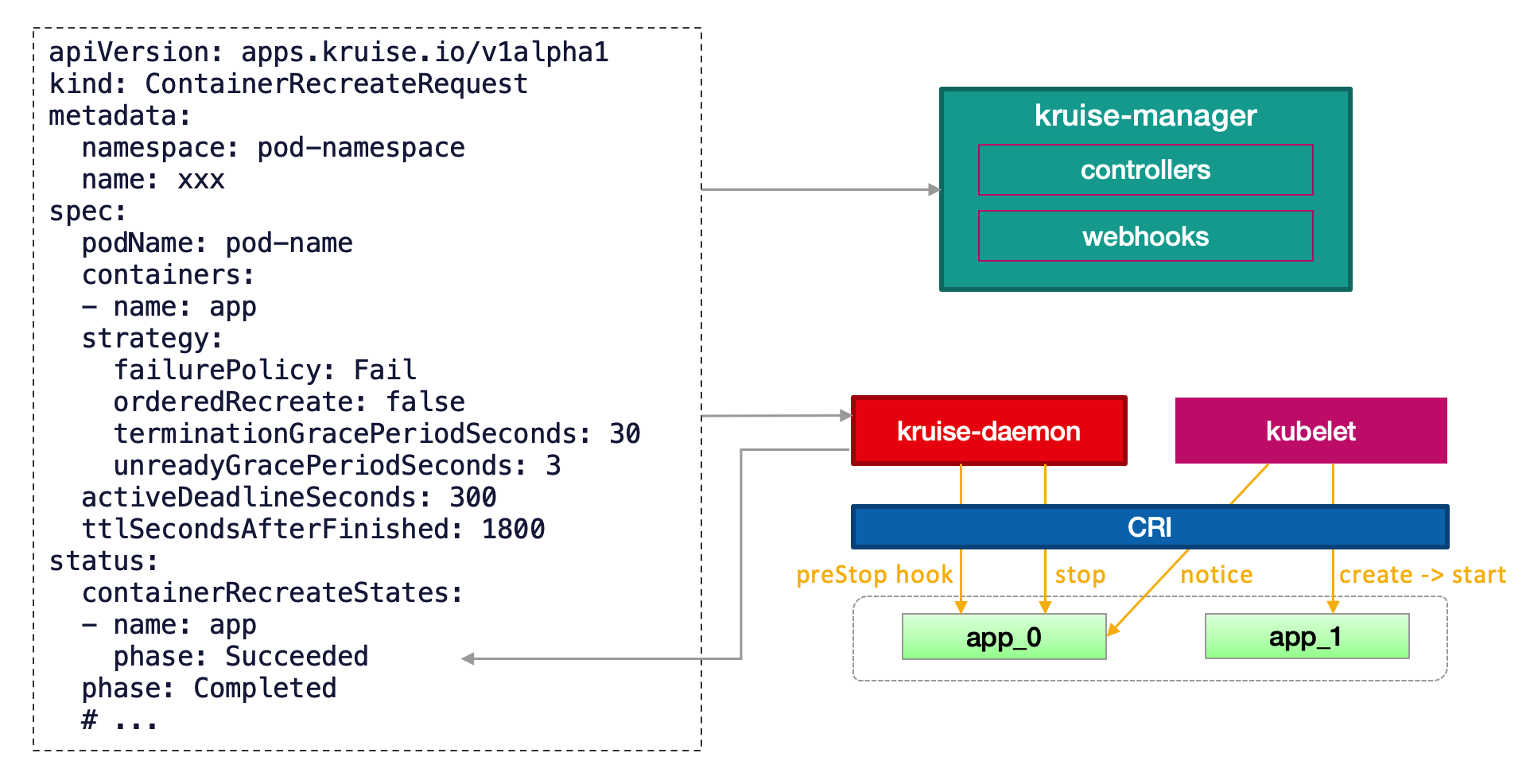
容器重启新增 forceRecreate 字段
当创建 CRR 资源时,如果容器正在启动过程中,CRR 将不会再重启容器。如果您想要强制重启容器,可以使用以下字段开启:
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
spec:
...
strategy:
forceRecreate: true
镜像预热支持 Attach metadata into cri interface
当 Kubelet 创建 Pod 时,Kubelet 将会 attach metadata 到 container runtime cri 接口。镜像仓库可以根据这些 metadata 信息来确定拉镜像的来源业务,如果发生了仓库过载、压力过大的情况,可以对具体的业务进行降级处理。OpenKruise 镜像预热同样支持类似的能力,如下:
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
sandboxConfig:
annotations:
io.kubernetes.image.metrics.tags: "cluster=cn-shanghai"
labels:
io.kubernetes.image.app: "foo"
社区参与
非常欢迎你通过 Github/Slack/钉钉/微信 等方式加入我们来参与 OpenKruise 开源社区。 你是否已经有一些希望与我们社区交流的内容呢? 可以在我们的社区双周会上分享你的声音,或通过以下渠道参与讨论:
- 加入社区 Slack channel (English)
- 加入社区钉钉群:搜索群号
23330762(Chinese) - 加入社区微信群(新):添加用户
openkruise并让机器人拉你入群 (Chinese)