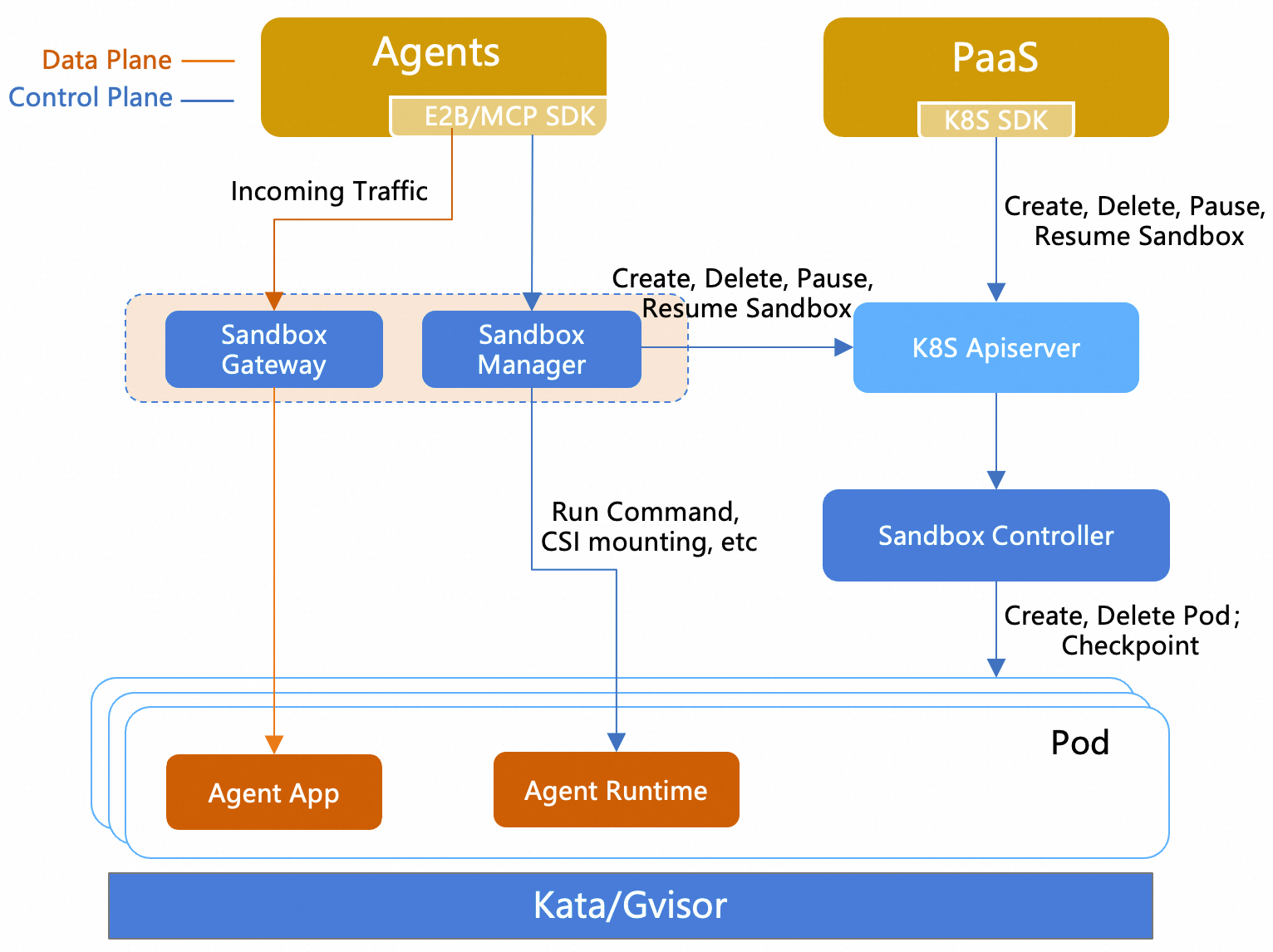
OpenKruise V1.9 版本发布:API v1beta1、定时镜像预拉取及更多新特性

OpenKruise( https://github.com/openkruise/kruise )是阿里云开源的云原生应用自动化管理套件,也是当前托管在 Cloud Native Computing Foundation (CNCF) 下的孵化项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,是阿里内部生产环境大规模应用的基于 Kubernetes 之上的标准扩展组件,也是紧贴上游社区标准、适应互联网规模化场景的技术理念与最佳实践。
OpenKruise 在 2026.6.21 发布了最新的 v1.9.0 版本(ChangeLog),本次发布带来了 API v1beta1 升级、Windows 节点支持,以及多项新特性。本文将详细介绍核心特性,并简要介绍其他重要变更。
升级须知
- Kubernetes 依赖已更新至 v1.32.6,Golang 更新至 v1.23,请确保集群兼容。
- API v1alpha1 → v1beta1:BroadcastJob、AdvancedCronJob、ImagePullJob、ImageListPullJob、NodeImage、Advanced DaemonSet 和 SidecarSet 的 API 已从 v1alpha1 升级至 v1beta1。v1alpha1 API 仍然支持但已废弃,转换 webhook 会自动处理迁移。强烈建议用户在升级到 OpenKruise v2.0 之前将清单更新为 v1beta1。
除了 apiVersion 变更外,升级过程中还修改了若干字段:
SidecarSet 字段变更:
spec.namespace已废弃——改用spec.namespaceSelector配合kubernetes.io/metadata.name标签。"apps.kruise.io/sidecarset-custom-version"注解被spec.customVersion字段替代。
# 升级前(v1alpha1)
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
annotations:
apps.kruise.io/sidecarset-custom-version: "v1"
spec:
namespace: default
# 升级后(v1beta1)
apiVersion: apps.kruise.io/v1beta1
kind: SidecarSet
metadata:
name: my-sidecarset
spec:
customVersion: v1
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
Advanced DaemonSet 字段变更:
"daemonset.kruise.io/progressive-create-pod"注解被spec.scaleStrategy替代。status.DaemonSetHash被status.UpdateRevision替代。spec.partition类型从*int32变为*intstr.IntOrString——现在支持百分比值,如50%。spec.updateStrategy.rollingUpdate.type: Surging已废弃——请使用Standard。
# 升级后(v1beta1)——partition 支持百分比
apiVersion: apps.kruise.io/v1beta1
kind: AdvancedDaemonSet
spec:
partition: "50%"
updateStrategy:
rollingUpdate:
type: Standard
完整的 API 升级和字段变更列表,请参阅 API 升级指南。
注意:Advanced StatefulSet 的 v1alpha1 API 将在 OpenKruise v2.0 中移除。其他 v1alpha1 API 暂无移除计划,但建议尽早迁移以避免转换 webhook 的性能开销。
核心特性
UnitedDeployment ReserveUnschedulablePods
在弹性场景中,用户通常希望优先将 Pod 调度到自有节点池(如自建 IDC),将弹性节点池(如 virtual-kubelet)作为兜底。现有的 Adaptive 策略在目标 Subset 不可调度时会永久将 Pod 调度到其他 Subset,这意味着即使原 Subset 恢复,Pod 也不会迁移回来。
v1.9.0 引入了 reserveUnschedulablePods 选项,在 Adaptive 调度策略下启用后,不可调度的 Pod 会被保留在目标 Subset 中,同时在下一个可用 Subset 中创建临时副本以维持期望副本数。当目标 Subset 恢复调度能力后,临时副本将被删除,保留的 Pod 会重新调度回原 Subset。
apiVersion: apps.kruise.io/v1alpha1
kind: UnitedDeployment
metadata:
name: sample-ud
spec:
topology:
scheduleStrategy:
type: Adaptive
adaptive:
reserveUnschedulablePods: true
rescheduleCriticalSeconds: 30
subsets:
- name: ecs
nodeSelectorTerm:
matchExpressions:
- key: node-type
operator: In
values: [ecs]
- name: vk
nodeSelectorTerm:
matchExpressions:
- key: node-type
operator: In
values: [virtual-kubelet]
在这个示例中,Pod 优先调度到 ECS 节点。当 ECS 节点资源不足时,会在 virtual-kubelet 节点上创建临时副本。当 ECS 容量恢复后(例如节点扩容),临时副本被删除,Pod 迁移回 ECS。
限制:仅在 Adaptive 调度策略下生效。临时副本的创建在 Subset 间递归执行。
AdvancedCronJob 定时 ImagePullJob
对于 AI/ML 等使用大镜像(数 GB 级别)的工作负载,在 Pod 调度前预拉取镜像可以显著减少启动时间。在大模型负载的集群中,节点经常因磁盘空间压力而 GC 镜像,因此需要在定时任务运行前重新预热,确保预热效果。此前,用户需要手动创建 ImagePullJob 资源或使用外部定时工具。现在可以直接在 AdvancedCronJob 中使用新增的 imageListPullJobTemplate 字段,将镜像预拉取作为定时任务调度。
apiVersion: apps.kruise.io/v1beta1
kind: AdvancedCronJob
metadata:
name: acj-image-pull
spec:
schedule: "0 */2 * * *"
concurrencyPolicy: Replace
template:
imageListPullJobTemplate:
spec:
parallelism: 5
images:
- nginx:1.14.2
- busybox:latest
pullSecrets:
- default-secret
selector:
names:
- node1
- node2
pullPolicy:
timeoutSeconds: 60
imagePullPolicy: IfNotPresent
这个示例每 2 小时创建一个 ImageListPullJob,在 node1 和 node2 上拉取指定镜像。concurrencyPolicy: Replace 确保新任务触发时,仍在运行的旧任务会被替换。
限制:使用 v1beta1 API。imageListPullJobTemplate 字段自 v1.9.0 起可用。
CloneSet progressDeadlineSeconds
在 CI/CD 流水线中,尽早检测发布失败非常重要。没有进度截止时间的情况下,卡住的发布(例如镜像拉取错误、就绪探针失败)可能无限期挂起而没有任何信号。v1.9.0 为 CloneSet 新增了 progressDeadlineSeconds 字段,类似原生 Kubernetes Deployment。
apiVersion: apps.kruise.io/v1beta1
kind: CloneSet
spec:
replicas: 10
progressDeadlineSeconds: 600
# ...
如果发布在 600 秒内未取得进展,CloneSet 控制器会在 .status.conditions 中添加以下条件:
type: Progressing
status: "False"
reason: ProgressDeadlineExceeded
上层编排系统(如 ArgoCD、Flux)可以监控此条件来触发自动回滚。
限制:该值必须大于 spec.minReadySeconds。此条件不会停止底层发布——它只是发出失败信号。暂停发布也会暂停截止时间检查。
SidecarSet 动态资源
Sidecar 容器(如服务网格代理、日志 Agent)通常需要与主容器成比例的资源。此前,用户必须为 sidecar 设置固定的资源请求/限制,这导致小 Pod 过度分配或大 Pod 分配不足。
v1.9.0 引入了 resourcesPolicy,允许通过表达式根据目标 Pod 容器资源来定义 sidecar 资源。
apiVersion: apps.kruise.io/v1beta1
kind: SidecarSet
spec:
containers:
- name: sidecar1
image: centos:6.7
resourcesPolicy:
targetContainersMode: sum
targetContainersNameRegex: ^large-engine-v4$
resourcesExpr:
limits:
cpu: max(cpu*50%, 50m)
memory: 200Mi
requests:
cpu: max(cpu*50%, 50m)
memory: 100Mi
在这个示例中,sidecar 的 CPU 设置为 large-engine-v4 容器 CPU 的 50%,最小为 50m。支持的表达式运算符包括 +、-、*、/、max()、min() 和 Kubernetes 资源量(如 50m、200Mi)。
限制:表达式中的 cpu 和 memory 变量代表根据 targetContainersMode(如 sum)和 targetContainersNameRegex 计算的目标容器聚合资源值。
PodUnavailableBudget RESIZE 保护
PodUnavailableBudget (PUB) 通过限制同时不可用的 Pod 数量来保护应用可用性。此前,PUB 保护 DELETE、EVICT 和 UPDATE 操作。随着原地垂直扩缩容(Kubernetes 1.27+ InPlacePodVerticalScaling)的普及,RESIZE 操作也可能导致 Pod 暂时不可用。
v1.9.0 新增 RESIZE 作为受保护的操作。可以通过注解控制受保护的操作类型:
apiVersion: policy.kruise.io/v1alpha1
kind: PodUnavailableBudget
metadata:
name: web-server-pub
annotations:
# 默认保护: DELETE, EVICT, UPDATE
# 添加 RESIZE 以保护原地资源调整
kruise.io/pub-protect-operations: "DELETE, EVICT, UPDATE, RESIZE"
spec:
targetRef:
apiVersion: apps.kruise.io/v1beta1
kind: CloneSet
name: web-server
maxUnavailable: 20%
限制:如果 InPlacePodVerticalScaling feature gate 未启用,原地资源调整将被视为 UPDATE 操作。
其他重要变更
以下特性也在 v1.9.0 中引入——详情请参阅文档:
- SidecarSet shareVolumeDevicePolicy:Sidecar 容器现在可以与 Pod 中其他容器共享块设备(VolumeDevices),类似于现有的用于卷挂载的
shareVolumePolicy。 - SidecarSet 注入顺序:SidecarSet 在注入时按名称升序对
containers和initContainers排序,确保有依赖关系的 sidecar 容器按正确顺序注入。 - PodProbeMarker HTTP 探针:除
exec和tcpSocket外,支持httpGet探针,无需通过 exec 包装curl即可直接进行 HTTP 健康检查。 - CloneSet OnDelete 策略:新增
podUpdatePolicy类型,仅在 Pod 被手动删除时才更新——适用于需要手动控制更新的有状态工作负载。 - JobSidecarTerminator 退出码控制:
KRUISE_TERMINATE_SIDECAR_IGNORE_EXIT_CODE环境变量允许显式控制 sidecar 的非零退出码是否影响 Pod Phase。 - ImagePullJob 节点侧并发控制:kruise-daemon 的
--max-concurrency标志限制每个节点的并发镜像拉取数量,防止资源耗尽。 - OpenKruise Daemon Windows 支持:kruise-daemon 现在支持 Windows 节点,使 CRR、镜像预拉取和 PodProbeMarker 可用于 Windows 工作负载。
其他改进
本版本包含多项 Bug 修复和稳定性改进。完整列表请参阅 changelog。
展望 v2.0
展望未来,下一个大版本(v2.0)将带来两项重要变更:
更多 API 升级到 v1beta1:CloneSet、WorkloadSpread、UnitedDeployment、PersistentPodState、PodUnavailableBudget、PodProbeMarker 和 NodePodProbe 将从 v1alpha1 升级到 v1beta1。此外,Advanced StatefulSet 的 v1alpha1 API 将在 v2.0 中移除。
ConfigMapSet——全新的配置灰度发布功能:ConfigMapSet 是目前正在 master 分支上积极开发的新 CRD。它支持与镜像发布解耦的零停机配置更新——可以更新配置数据(如 YAML 文件、环境变量)并逐步灰度发布,无需重新构建镜像。核心能力包括:
- 版本管理:维护配置版本的修订历史,支持回滚到之前的版本。
- 配置灰度:通过
updateStrategy中的partition控制灰度比例,实现配置的渐进式更新。 - 容器选择:支持静态容器名称和通过字段引用的动态选择(兼容 SidecarSet 注入)。
- 更新策略:两种模式——仅注入(默认)模式下 reload sidecar 更新配置但不重启容器;
restartInjectedContainers模式下使用配置的容器也会被重启。
apiVersion: apps.kruise.io/v1alpha1
kind: ConfigMapSet
metadata:
name: deploy-cms
spec:
selector:
matchLabels:
app: sample
data:
settings.yaml: |
value: aaa
containers:
- name: main
mountPath: /data/conf
revisionHistoryLimit: 5
updateStrategy:
partition: 10%
restartInjectedContainers: true
maxUnavailable: 1
注意:ConfigMapSet 仍在积极开发中。API 和功能集在正式发布前可能会有变化。
参与社区
欢迎通过 Github/Slack/DingTalk/WeChat 参与 OpenKruise 社区。 有什么想向社区广播的内容吗? 在我们的双周社区会议(中文)上分享您的声音,或通过以下渠道:
- 在 Slack 上加入社区(英文)。
- 在钉钉上加入社区:搜索群号
23330762(中文)。 - 在微信上加入社区(新):搜索用户
openkruise并让机器人邀请您(中文)。