UnitedDeploymemt - Supporting Multi-domain Workload Management

Ironically, probably every cloud user knew (or should realized that) failures in Cloud resources are inevitable. Hence, high availability is probably one of the most desirable features that Cloud Provider offers for cloud users. For example, in AWS, each geographic region has multiple isolated locations known as Availability Zones (AZs). AWS provides various AZ-aware solutions to allow the compute or storage resources of the user applications to be distributed across multiple AZs in order to tolerate AZ failure, which indeed happened in the past.
In Kubernetes, the concept of AZ is not realized by an API object. Instead,
an AZ is usually represented by a group of hosts that have the same location label.
Although hosts within the same AZ can be identified by labels, the capability of distributing Pods across
AZs was missing in Kubernetes default scheduler. Hence it was difficult to use single
StatefulSet or Deployment to perform AZ-aware Pods deployment. Fortunately,
in Kubernetes 1.16, a new feature called "Pod Topology Spread Constraints"
was introduced. Users now can add new constraints in the Pod Spec, and scheduler
will enforce the constraints so that Pods can be distributed across failure
domains such as AZs, regions or nodes, in a uniform fashion.
In Kruise, UnitedDeploymemt provides an alternative to achieve high availability in
a cluster that consists of multiple fault domains - that is, managing multiple homogeneous
workloads, and each workload is dedicated to a single Subset. Pod distribution across AZs is
determined by the replica number of each workload.
Since each Subset is associated with a workload, UnitedDeployment can support
finer-grained rollout and deployment strategies.
In addition, UnitedDeploymemt can be further extended to support
multiple clusters! Let us reveal how UnitedDeployment is designed.
Using Subsets to describe domain topology
UnitedDeploymemt uses Subset to represent a failure domain. Subset API
primarily specifies the nodes that forms the domain and the number of replicas, or
the percentage of total replicas, run in this domain. UnitedDeployment manages
subset workloads against a specific domain topology, described by a Subset array.
type Topology struct {
// Contains the details of each subset.
Subsets []Subset
}
type Subset struct {
// Indicates the name of this subset, which will be used to generate
// subset workload name prefix in the format '<deployment-name>-<subset-name>-'.
Name string
// Indicates the node select strategy to form the subset.
NodeSelector corev1.NodeSelector
// Indicates the number of the subset replicas or percentage of it on the
// UnitedDeployment replicas.
Replicas *intstr.IntOrString
}
The specification of the subset workload is saved in Spec.Template. UnitedDeployment
only supports StatefulSet subset workload as of now. An interesting part of Subset
design is that now user can specify customized Pod distribution across AZs, which is not
necessarily a uniform distribution in some cases. For example, if the AZ
utilization or capacity are not homogeneous, evenly distributing Pods may lead to Pod deployment
failure due to lack of resources. If users have prior knowledge about AZ resource capacity/usage,
UnitedDeployment can help to apply an optimal Pod distribution to ensure overall
cluster utilization remains balanced. Of course, if not specified, a uniform Pod distribution
will be applied to maximize availability.
Customized subset rollout Partitions
User can update all the UnitedDeployment subset workloads by providing a
new version of subset workload template.
Note that UnitedDeployment does not control
the entire rollout process of all subset workloads, which is typically done by another rollout
controller built on top of it. Since the replica number in each Subset can be different,
it will be much more convenient to allow users to specify the individual rollout Partition of each
subset workload instead of using one Partition to rule all, so that they can be upgraded in the same pace.
UnitedDeployment provides ManualUpdate strategy to customize per subset rollout Partition.
type UnitedDeploymentUpdateStrategy struct {
// Type of UnitedDeployment update.
Type UpdateStrategyType
// Indicates the partition of each subset.
ManualUpdate *ManualUpdate
}
type ManualUpdate struct {
// Indicates number of subset partition.
Partitions map[string]int32
}
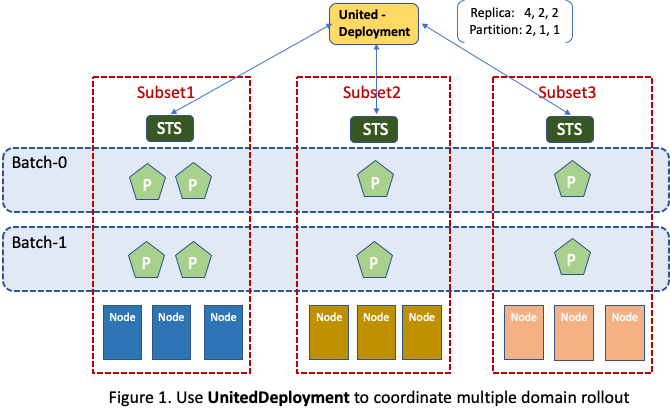
This makes it fairly easy to coordinate multiple subsets rollout. For example,
as illustrated in Figure 1, assuming UnitedDeployment manages three subsets and
their replica numbers are 4, 2, 2 respectively, a rollout
controller can realize a canary release plan of upgrading 50% of Pods in each
subset at a time by setting subset partitions to 2, 1, 1 respectively.
The same cannot be easily achieved by using a single workload controller like StatefulSet
or Deployment.
Multi-Cluster application management (In future)
UnitedDeployment can be extended to support multi-cluster workload
management. The idea is that Subsets may not only
reside in one cluster, but also spread over multiple clusters.
More specifically, domain topology specification will associate
a ClusterRegistryQuerySpec, which describes the clusters that UnitedDeployment
may distribute Pods to. Each cluster is represented by a custom resource managed by a
ClusterRegistry controller using Kubernetes cluster registry APIs.
type Topology struct {
// ClusterRegistryQuerySpec is used to find the all the clusters that
// the workload may be deployed to.
ClusterRegistry *ClusterRegistryQuerySpec
// Contains the details of each subset including the target cluster name and
// the node selector in target cluster.
Subsets []Subset
}
type ClusterRegistryQuerySpec struct {
// Namespaces that the cluster objects reside.
// If not specified, default namespace is used.
Namespaces []string
// Selector is the label matcher to find all qualified clusters.
Selector map[string]string
// Describe the kind and APIversion of the cluster object.
ClusterType metav1.TypeMeta
}
type Subset struct {
Name string
// The name of target cluster. The controller will validate that
// the TargetCluster exits based on Topology.ClusterRegistry.
TargetCluster *TargetCluster
// Indicate the node select strategy in the Subset.TargetCluster.
// If Subset.TargetCluster is not set, node selector strategy refers to
// current cluster.
NodeSelector corev1.NodeSelector
Replicas *intstr.IntOrString
}
type TargetCluster struct {
// Namespace of the target cluster CRD
Namespace string
// Target cluster name
Name string
}
A new TargetCluster field is added to the Subset API. If it presents, the
NodeSelector indicates the node selection logic in the target cluster. Now
UnitedDeployment controller can distribute application Pods to multiple clusters by
instantiating a StatefulSet workload in each target cluster with a specific
replica number (or a percentage of total replica), as illustrated in Figure 2.
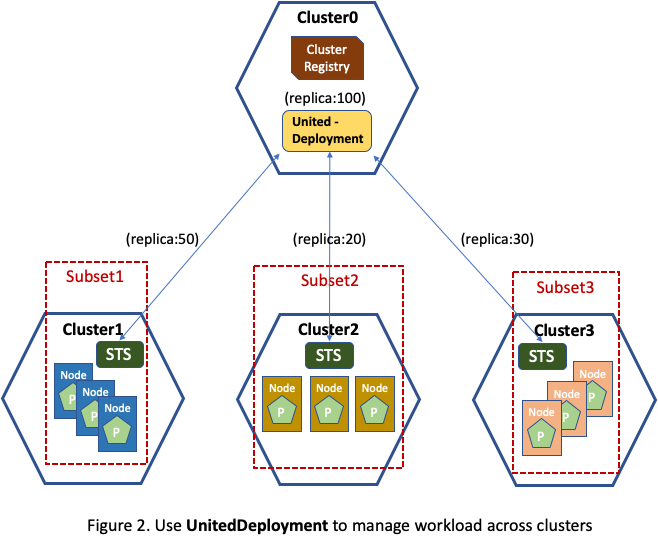
At a first glance, UnitedDeployment looks more like a federation
controller following the design pattern of Kubefed,
but it isn't. The fundamental difference is that Kubefed focuses on propagating arbitrary
object types to remote clusters instead of managing an application across clusters.
In this example, had a Kubefed style controller been used, each StatefulSet workload in
individual cluster would have a replica of 100. UnitedDeployment focuses more on
providing the ability of managing multiple workloads in multiple clusters on behalf
of one application, which is absent in Kubernetes community to the best of our
knowledge.
Summary
This blog post introduces UnitedDeployment, a new controller which helps managing application spread over multiple domains (in arbitrary clusters). It not only allows evenly distributing Pods over AZs, which arguably can be more efficiently done using the new Pod Topology Spread Constraint APIs though, but also enables flexible workload deployment/rollout and supports multi-cluster use cases in the future.