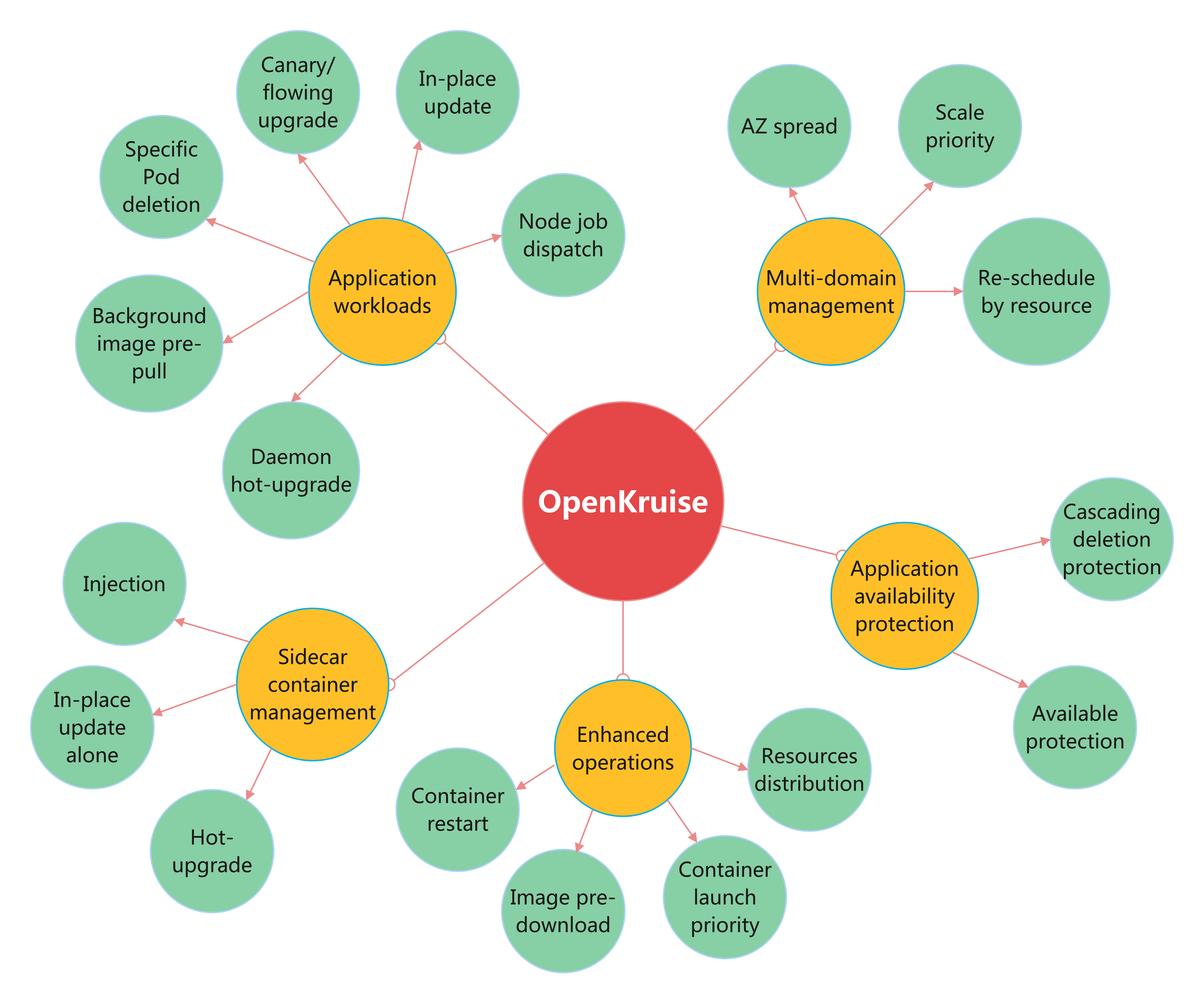
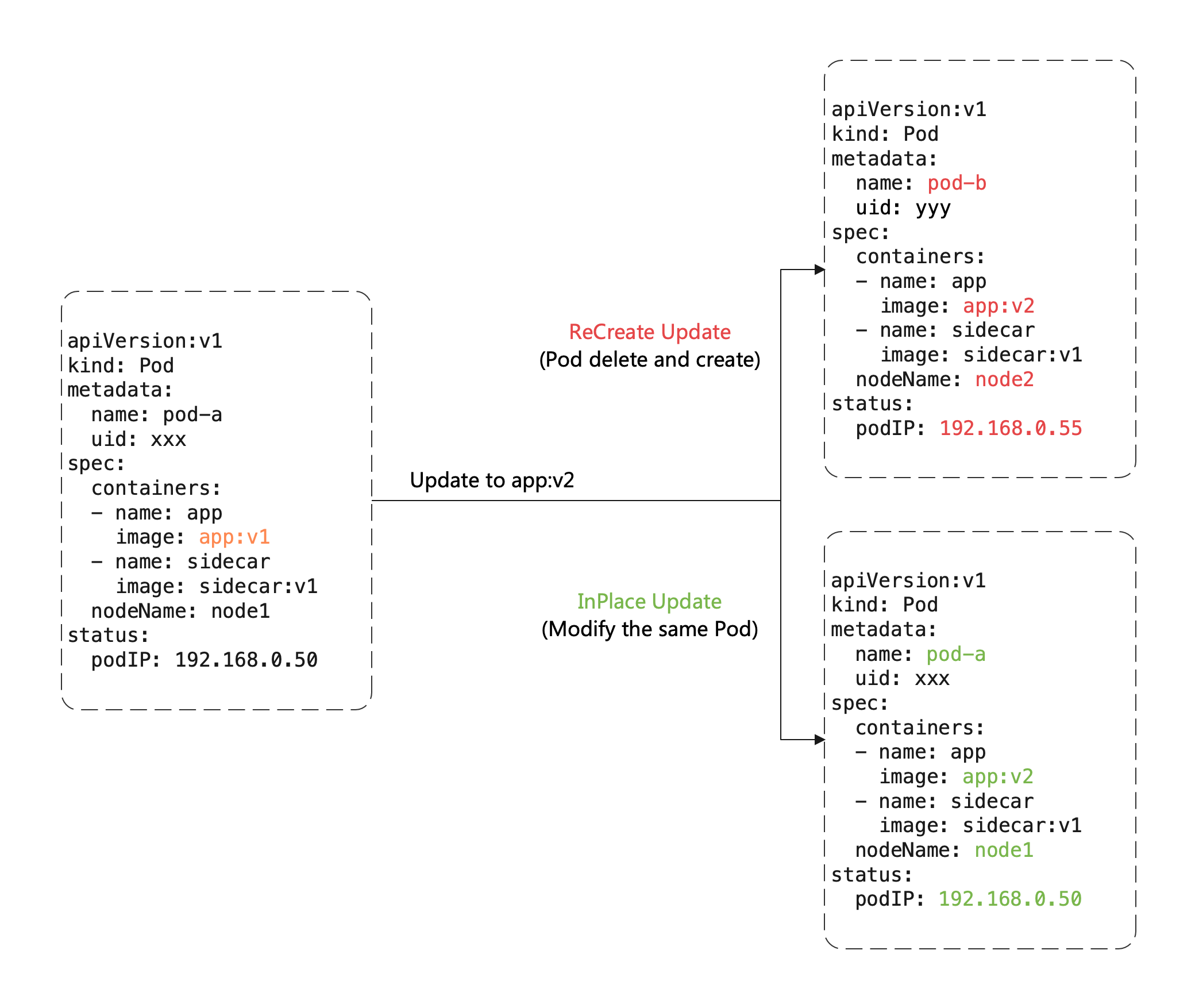
OpenKruise (https://github.com/openkruise/kruise) is an open-source cloud-native application automation management suite. It is also a current incubating project hosted by the Cloud Native Computing Foundation (CNCF). It is a standard extension component based on Kubernetes that is widely used in production of internet scale company. It also closely follows upstream community standards and adapts to the technical improvement and best practices for internet-scale scenarios.
OpenKruise has released the latest version v1.4 on March 31, 2023 (ChangeLog), with the addition of the Job Sidecar Terminator feature. This article provides a comprehensive overview of the new version.
Upgrade Notice
- To facilitate the use of Kruise's enhanced capabilities, some stable capabilities have been enabled by default, including ResourcesDeletionProtection, WorkloadSpread, PodUnavailableBudgetDeleteGate, InPlaceUpdateEnvFromMetadata, StatefulSetAutoDeletePVC, and PodProbeMarkerGate. Most of these capabilities require special configuration to take effect, so enabling them by default generally has no impact on existing clusters. If you do not want to use some of these features, you can turn them off during the upgrade process.
- The leader election method for Kruise-Manager has been migrated from configmaps to configmapsleases to prepare for future migration to the leases method. In addition, this is an officially provided smooth upgrade method that will not affect existing clusters.
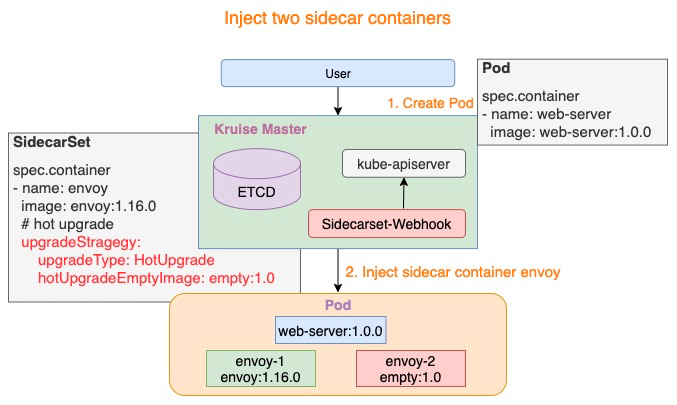
2. New Job Sidecar Terminator Capability
In Kubernetes, for Job workloads, it is commonly desired that when the main container completes its task and terminates, the Pod should enter a completed state. However, when these Pods have Long-Running Sidecar containers, the Sidecar container cannot terminate itself after the main container has exited, causing the Pod to remain in an incomplete state. The community's common solution to this problem usually involves modifying both the Main and Sidecar containers to use Volume sharing to achieve the effect of the Sidecar container exiting after the Main container has completed.
While the community's solution can solve this problem, it requires modification of the containers, especially for commonly used Sidecar containers, which incurs high costs for modification and maintenance.
To address this, we have added a controller called SidecarTerminator to Kruise. This controller is specifically designed to listen for completion status of the main container in this scenario and select an appropriate time to terminate the Sidecar container in the Pod, without requiring intrusive modification of the Main and Sidecar containers.
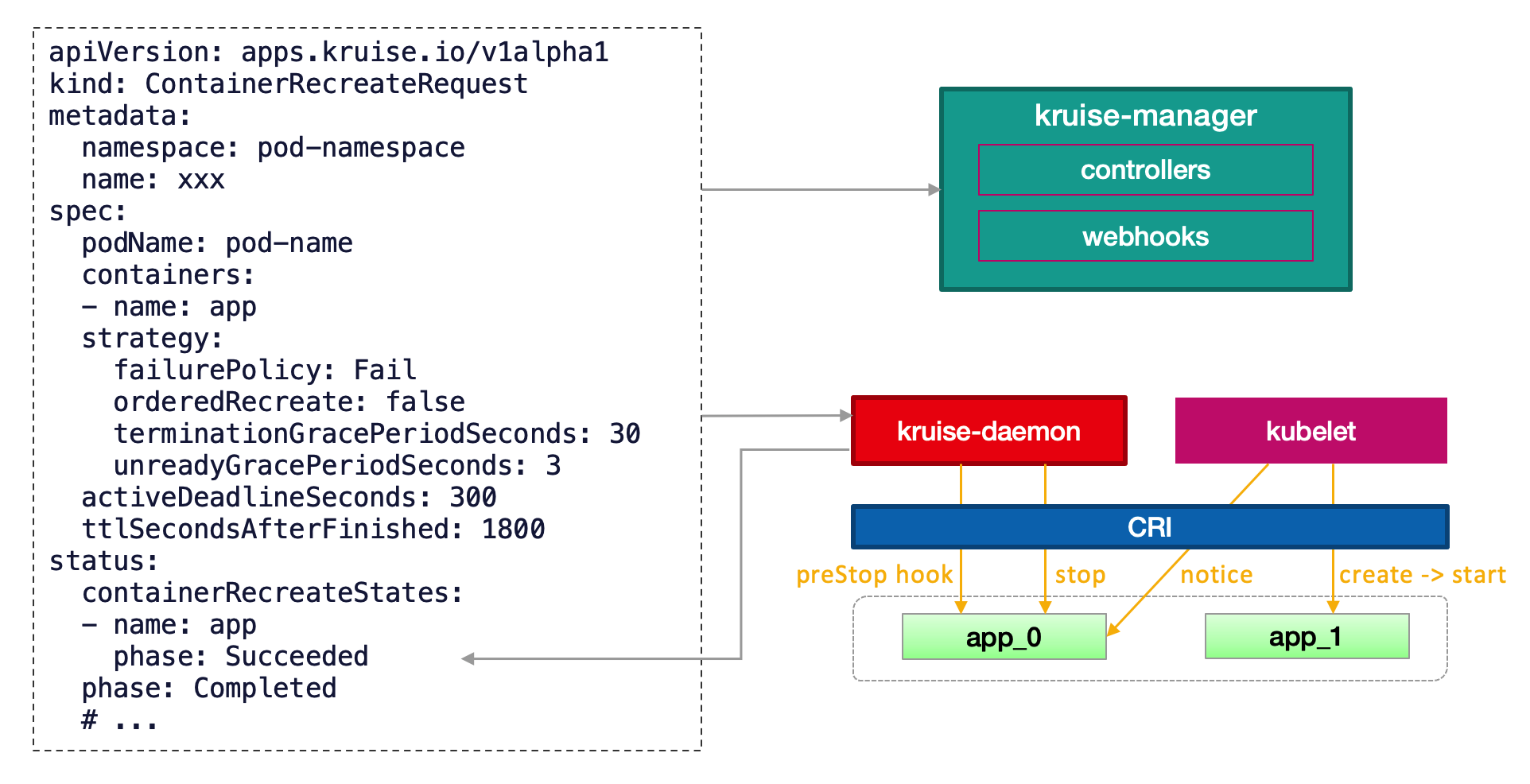
Pods on real nodes
For pods running on regular nodes, it is very easy to use this feature since Kruise daemon can be installed. Users just need to add a special env to identify the target sidecar container in the pod, and the controller will use the ContainerRecreateRequest(CRR) capability provided by Kruise Daemon to terminate these sidecar containers at the appropriate time.
kind: Job
spec:
template:
spec:
containers:
- name: sidecar
env:
- name: KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT
value: "true"
- name: main
...
Pods on virtual nodes
For some platforms that provide Serverless containers, such as ECI or Fargate, their pods can only run on virtual nodes such as Virtual-Kubelet. However, Kruise Daemon cannot be deployed and work on these virtual nodes, which makes it impossible to use the CRR capability to terminate containers.
Fortunately, we can use the Pod in-place upgrade mechanism provided by native Kubernetes to achieve the same goal: just construct a special image whose only purpose is to make the container exit quickly once started. In this way, when exiting the sidecar, just replace the original sidecar image with the fast exit image to achieve the purpose of exiting the sidecar.
Step 1: Prepare a fast exit image
- The image only needs to have a very simple logic: when the container of this image starts, it exits directly with an exit code of 0.
- The image needs to be compatible with the commands and args of the original sidecar image to prevent errors when the container starts.
Step 2: Configure the special image in the Sidecar environment variable
kind: Job
spec:
template:
spec:
containers:
- name: sidecar
env:
- name: KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT_WITH_IMAGE
value: "example/quick-exit:v1.0.0"
- name: main
...
Replace "example/quick-exit:v1.0.0" with the fast exit image that you have prepared in step 1.
Notice
- The sidecar container must be able to respond to the SIGTERM signal, and when it receives this signal, the entrypoint process needs to exit (that is, the sidecar container needs to exit), and the exit code should be 0.
- This feature applies to any Pod managed by a Job type Workload, as long as their RestartPolicy is Never/OnFailure.
- Containers with the environment variable KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT will be treated as sidecar containers, while other containers will be treated as main containers. The sidecar container will only be terminated after all main containers have completed:
- Under the Never restart policy, once the main container exits, it will be considered "completed".
- Under the OnFailure restart policy, the exit code of the main container must be 0 to be considered "completed".
- In Pods on real nodes mode,
KRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIThas a higher priority thanKRUISE_TERMINATE_SIDECAR_WHEN_JOB_EXIT_WITH_IMAGE
Advanced Workload Improvement
CloneSet Optimization Performance: New FeatureGate CloneSetEventHandlerOptimization
Currently, whether it's a change in the state or metadata of a Pod,, the Pod Update event will trigger the CloneSet reconcile logic. CloneSet Reconcile is configured with three workers by default, which is not a problem for smaller cluster scenarios.
However, for larger or busy clusters, these unneccesary reconciles will block the true CloneSet reconcile and delay changes such as rolling updates of CloneSet. To solve this problem, you can turn on the feature-gate CloneSetEventHandlerOptimization to reduce some unnecessary enqueueing of reconciles.
CloneSet New disablePVCReuse Field
If a Pod is directly deleted or evicted by other controller or user, the PVCs associated with the Pod still remain. When the CloneSet controller creates new Pods, it will reuse existing PVCs.
However, if the Node where the Pod is located experiences a failure, reusing existing PVCs may cause the new Pod to fail to start. For details, please refer to issue 1099. To solve this problem, you can set the disablePVCReuse=true field. After the Pod is evicted or deleted, the PVCs associated with the Pod will be automatically deleted and will no longer be reused.
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
...
replicas: 4
scaleStrategy:
disablePVCReuse: true
CloneSet New PreNormal Lifecycle
CloneSet currently supports two lifecycle hooks, PreparingUpdate and PreparingDelete, which are used for graceful application termination. For details, please refer to the Community Documentation. In order to support graceful application deployment, a new state called PreNormal has been added, as follows:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# define with finalizer
lifecycle:
preNormal:
finalizersHandler:
- example.io/unready-blocker
# or define with label
# lifecycle:
# preNormal:
# labelsHandler:
# example.io/block-unready: "true"
When CloneSet creates a Pod (including normal scaling and upgrades):
- The Pod will only be considered "Available" and enter the "Normal" state if it meets the definition of the PreNormal hook.
This is useful for some post-checks when creating Pods, such as checking if the Pod has been mounted to the SLB backend, so as to avoid traffic loss caused by new instance mounting failure after the old instance is destroyed during rolling upgrade.
4. Enhanced Operations Improvement
ContainerRestart New forceRecreate Field
When creating a CRR resource, if the container is in the process of starting up, the CRR will not restart the container again. If you want to force a container restart, you can enable the following field:
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
spec:
...
strategy:
forceRecreate: true
ImagePullJob Support Attach metadata into cri interface
When Kubelet creates a Pod, Kubelet will attach metadata to the container runtime using CRI interface. The image repository can use this metadata information to identify the business related to the starting container. Some container actions of low business value can be degraded to protect the overloaded repository.
OpenKruise's imagePullJob also supports similar capabilities, as follows:
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
spec:
...
image: nginx:1.9.1
sandboxConfig:
annotations:
io.kubernetes.image.metrics.tags: "cluster=cn-shanghai"
labels:
io.kubernetes.image.app: "foo"
Get Involved
Welcome to get involved with OpenKruise by joining us in Github/Slack/DingTalk/WeChat. Have something you’d like to broadcast to our community? Share your voice at our Bi-weekly community meeting (Chinese), or through the channels below:
- Join the community on Slack (English).
- Join the community on DingTalk: Search GroupID
23330762(Chinese). - Join the community on WeChat (new): Search User
openkruiseand let the robot invite you (Chinese).