OpenKruise 0.9.0, Supports Pod Restart and Deletion Protection

On May 20, 2021, OpenKruise released the latest version v0.9.0, with new features, such as Pod restart and resource cascading deletion protection. This article provides an overview of this new version.
Pod Restart and Recreation
Restarting container is a necessity in daily operation and a common technical method for recovery. In the native Kubernetes, the container granularity is inoperable. Pod, as the minimum operation unit, can only be created or deleted.
Some may ask: why do users still need to pay attention to the operation such as container restart in the cloud-native era? Aren't the services the only thing for users to focus on in the ideal Serverless model?
To answer this question, we need to see the differences between cloud-native architecture and traditional infrastructures. In the era of traditional physical and virtual machines, multiple application instances are deployed and run on one machine, but the lifecycles of the machine and applications are separated. Thus, application instance restart may only require a systemctl or supervisor command but not the restart of the entire machine. However, in the era of containers and cloud-native, the lifecycle of the application is bound to that of the Pod container. In other words, under normal circumstances, one container only runs one application process, and one Pod provides services for only one application instance.
Due to these restrictions, current native Kubernetes provides no API for the container (application) restart for upper-layer services. OpenKruise v0.9.0 supports restarting containers in a single Pod, compatible with standard Kubernetes clusters of version 1.16 or later. After installing or upgrading OpenKruise, users only need to create a ContainerRecreateRequest (CRR) object to initiate a restart process. The simplest YAML file is listed below:
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
metadata:
namespace: pod-namespace
name: xxx
spec:
podName: pod-name
containers:
- name: app
- name: sidecar
The value of namespace must be the same as the namespace of the Pod to be operated. The name can be set as needed. The podName in the spec clause indicates the Pod name. The containers indicate a list that specifies one or more container names in the Pod to restart.
In addition to the required fields above, CRR also provides a variety of optional restart policies:
spec:
# ...
strategy:
failurePolicy: Fail
orderedRecreate: false
terminationGracePeriodSeconds: 30
unreadyGracePeriodSeconds: 3
minStartedSeconds: 10
activeDeadlineSeconds: 300
ttlSecondsAfterFinished: 1800
failurePolicy: Values: Fail or Ignore. Default value: Fail. If any container stops or fails to recreate, CRR ends immediately.orderedRecreate: Default value: false. Value true indicates when the list contains multiple containers, the new container will only be recreated after the previous recreation is finished.terminationGracePeriodSeconds: The time for the container to gracefully exit. If this parameter is not specified, the time defined for the Pod is used.unreadyGracePeriodSeconds: Set the Pod to the unready state before recreation and wait for the time expiration to execute recreation.Note: This feature needs the feature-gateKruisePodReadinessGateto be enabled, which will inject a readinessGate when a Pod is created. Otherwise, only the pods created by the OpenKruise workload are injected with readinessGate by default. It means only these Pods can use theunreadyGracePeriodSecondsparameter during the CRR recreation.
minStartedSeconds: The minimal period that the new container remains running to judge whether the container is recreated successfully.activeDeadlineSeconds: The expiration period set for CRR execution to mark as ended (unfinished container will be marked as failed.)ttlSecondsAfterFinished: The period after which the CRR will be deleted automatically after the execution ends.
How it works under the hood: After it is created, a CRR is processed by the kruise-manager. Then, it will be sent to the kruise-daemon (contained by the node where Pod resides) for execution. The execution process is listed below:
- If
preStopis specified for a Pod, the kruise-daemon will first call the CRI to run the command specified bypreStopin the container. - If no
preStopexists orpreStopexecution is completed, the kruise-daemon will call the CRI to stop the container. - When the kubelet detects the container exiting, it creates a new container with an increasing "serial number" and starts it.
postStartwill be executed at the same time. - When the kruise-daemon detects the start of the new container, it reports to CRR that the restart is completed.
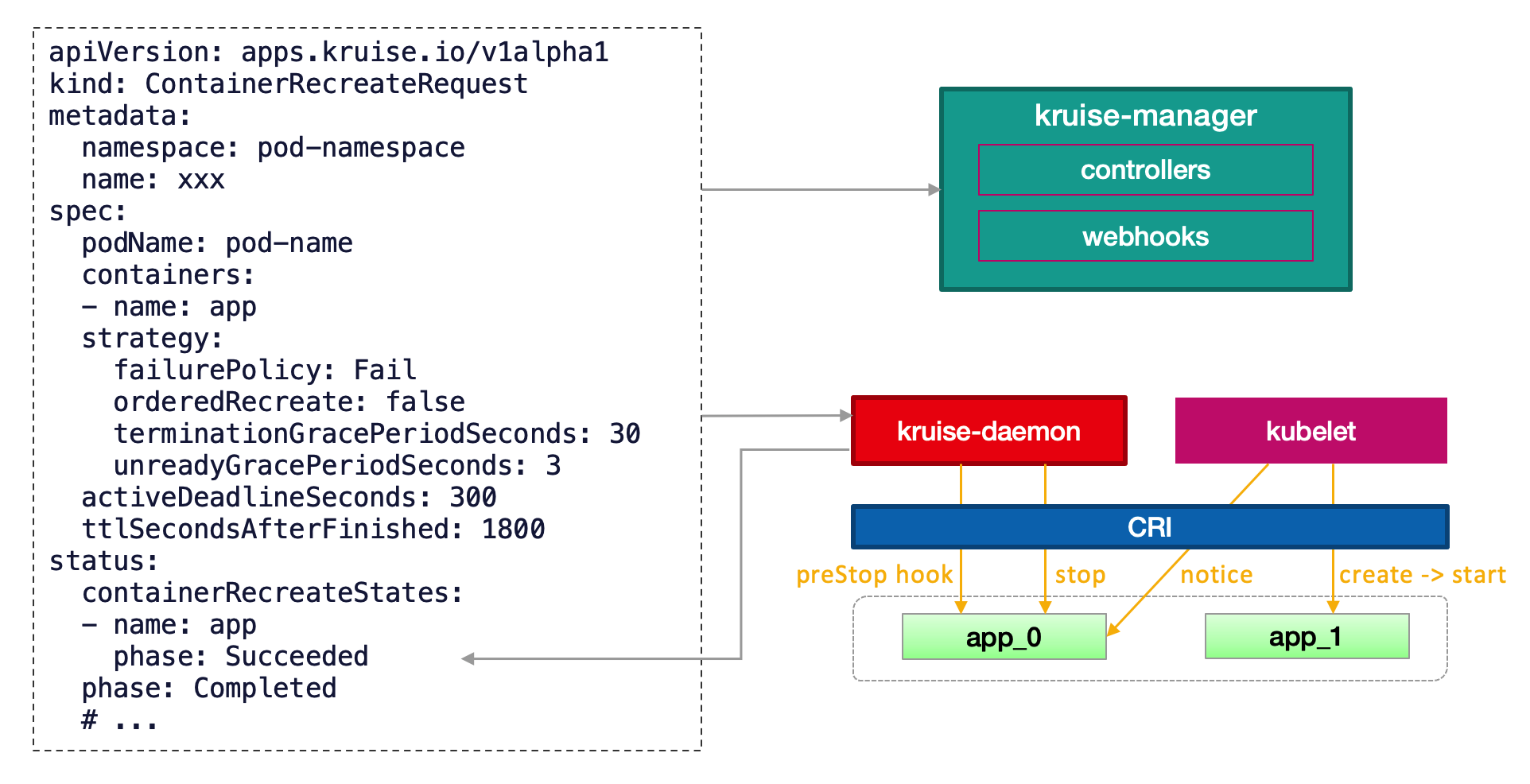
The container "serial number" corresponds to the restartCount reported by kubelet in the Pod status. Therefore, the restartCount of the Pod increases after the container is restarted. Temporary files written to the rootfs in the old container will be lost due to the container recreation, but data in the volume mount remains.
Cascading Deletion Protection
The level triggered automation of Kubernetes is a double-edged sword. It brings declarative deployment capabilities to applications while potentially enlarging the influence of mistakes at a final-state scale. For example, with the cascading deletion mechanism, once an owning resource is deleted under normal circumstances (non-orphan deletion), all owned resources associated will be deleted by the following rules:
- If a CRD is deleted, all its corresponding CR will be cleared.
- If a namespace is deleted, all resources in this namespace, including Pods, will be cleared.
- If a workload (Deployment, StatefulSet, etc) is deleted, all Pods under it will be cleared.
Due to failures caused by cascading deletion, we have heard many complaints from Kubernetes users and developers in the community. It is unbearable for any enterprise to mistakenly delete objects at such a large scale in the production environment.
Therefore, in OpenKruise v0.9.0, we applied the feature of cascading deletion protection to community in the hope of ensuring stability for more users. If you want to use this feature in the current version, the feature-gate of ResourcesDeletionProtection needs to be explicitly enabled when installing or upgrading OpenKruise.
A label of policy.kruise.io/delete-protection can be given on the resource objects that require protection. Its value can be the following two things:
- Always: The object cannot be deleted unless the label is removed.
- Cascading: The object cannot be deleted if any subordinate resources are available.
The following table lists the supported resource types and cascading relationships:
| Kind | Group | Version | Cascading judgment |
|---|---|---|---|
Namespace | core | v1 | whether there is active Pods in this namespace |
CustomResourceDefinition | apiextensions.k8s.io | v1beta1, v1 | whether there is existing CRs of this CRD |
Deployment | apps | v1 | whether the replicas is 0 |
StatefulSet | apps | v1 | whether the replicas is 0 |
ReplicaSet | apps | v1 | whether the replicas is 0 |
CloneSet | apps.kruise.io | v1alpha1 | whether the replicas is 0 |
StatefulSet | apps.kruise.io | v1alpha1, v1beta1 | whether the replicas is 0 |
UnitedDeployment | apps.kruise.io | v1alpha1 | whether the replicas is 0 |
New Features of CloneSet
Deletion Priority
The controller.kubernetes.io/pod-deletion-cost annotation was added to Kubernetes after version 1.21. ReplicaSet will sort the Kubernetes resources according to this cost value during scale in. CloneSet has supported the same feature since OpenKruise v0.9.0.
Users can configure this annotation in the pod. The int type of its value indicates the deletion cost of a certain pod compared to other pods under the same CloneSet. Pods with a lower cost have a higher deletion priority. If this annotation is not set, the deletion cost of the pod is 0 by default.
Note: This deletion order is not determined solely by deletion cost. The real order serves like this:
- Not scheduled < scheduled
- PodPending < PodUnknown < PodRunning
- Not ready < ready
- Smaller pod-deletion cost < larger pod-deletion cost
- Period in the Ready state: short < long
- Containers restart: more times < fewer times
- Creation time: short < long
Image Pre-Download for In-Place Update
When CloneSet is used for the in-place update of an application, only the container image is updated, while the Pod is not rebuilt. This ensures that the node where the Pod is located will not change. Therefore, if the CloneSet pulls the new image from all the Pod nodes in advance, the Pod in-place update speed will be improved substantially in subsequent batch releases.
If you want to use this feature in the current version, the feature-gate of PreDownloadImageForInPlaceUpdate needs to be explicitly enabled when installing or upgrading OpenKruise. If you update the images in the CloneSet template and the publish policy supports in-place update, CloneSet will create an ImagePullJob object automatically (the batch image pre-download function provided by OpenKruise) to download new images in advance on the node where the Pod is located.
By default, CloneSet sets the parallelism to 1 for ImagePullJob, which means images are pulled for one node and then another. For any adjustment, you can set the parallelism in the CloneSet annotation by executing the following code:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "5"
Pod Replacement by Scale Out and Scale In
In previous versions, the maxUnavailable and maxSurge policies of CloneSet only take effect during the application release process. In OpenKruise v0.9.0 and later versions, these two policies also function when deleting a specified Pod.
When the user specifies one or more Pods to be deleted through podsToDelete or apps.kruise.io/specified-delete: true, CloneSet will only execute deletion when the number of unavailable Pods (of the total replicas) is less than the value of maxUnavailable. In addition, if the user has configured the maxSurge policy, the CloneSet will possibly create a new Pod first, wait for the new Pod to be ready, and then delete the old specified Pod.
The replacement method depends on the value of maxUnavailable and the number of unavailable Pods. For example:
- For a CloneSet,
maxUnavailable=2, maxSurge=1and onlypod-ais unavailable. If you specifypod-bto be deleted, CloneSet will delete it promptly and create a new Pod. - For a CloneSet,
maxUnavailable=1, maxSurge=1and onlypod-ais unavailable. If you specifypod-bto be deleted, CloneSet will create a new Pod, wait for it to be ready, and then delete the pod-b. - For a CloneSet,
maxUnavailable=1, maxSurge=1and onlypod-ais unavailable. If you specify thispod-ato be deleted, CloneSet will delete it promptly and create a new Pod.
Efficient Rollback Based on Partition Final State
In the native workload, Deployment does not support phased release, while StatefulSet provides partition semantics to allow users to control the times of gray scale upgrades. OpenKruise workloads, such as CloneSet and Advanced StatefulSet, also provide partitions to support phased release.
For CloneSet, the semantics of Partition is the number or percentage of Pods remaining in the old version. For example, for a CloneSet with 100 replicas, if the partition value is changed in the sequence of 80 ➡️ 60 ➡️ 40 ➡️ 20 ➡️ 0 by steps during the image upgrade, the CloneSet is released in five batches.
However, in the past, whether it is Deployment, StatefulSet, or CloneSet, if rollback is required during the release process, the template information (image) must be changed back to the old version. During the phased release of StatefulSet and CloneSet, reducing partition value will trigger the upgrade to a new version. Increasing partition value will not trigger rollback to the old version.
The partition of CloneSet supports the "final state rollback" function after v0.9.0. If the feature-gate CloneSetPartitionRollback is enabled when installing or upgrading OpenKruise, increasing the partition value will trigger CloneSet to roll back the corresponding number of new Pods to the old version.
There is a clear advantage here. During the phased release, only the partition value needs to be adjusted to flexibly control the numbers of old and new versions. However, the "old and new versions" for CloneSet correspond to updateRevision and currentRevision in its status:
- updateRevision: The version of the template defined by the current CloneSet.
- currentRevision: The template version of CloneSet during the previous successful full release.
Short Hash
By default, the value of controller-revision-hash in Pod label set by CloneSet is the full name of the ControllerRevision. For example:
apiVersion: v1
kind: Pod
metadata:
labels:
controller-revision-hash: demo-cloneset-956df7994
The name is concatenated with the CloneSet name and the ControllerRevision hash value. Generally, the hash value is 8 to 10 characters in length. In Kubernetes, a label cannot exceed 63 characters in length. Therefore, the name of CloneSet cannot exceed 52 characters in length, or the Pod cannot be created.
In v0.9.0, the new feature-gate CloneSetShortHash is introduced. If it is enabled, CloneSet will set the value of controller-revision-hash in the Pod to a hash value only, like 956df7994. Therefore, the length restriction of the CloneSet name is eliminated. (CloneSet can still recognize and manage the Pod with revision labels in the full format, even if this function is enabled.)
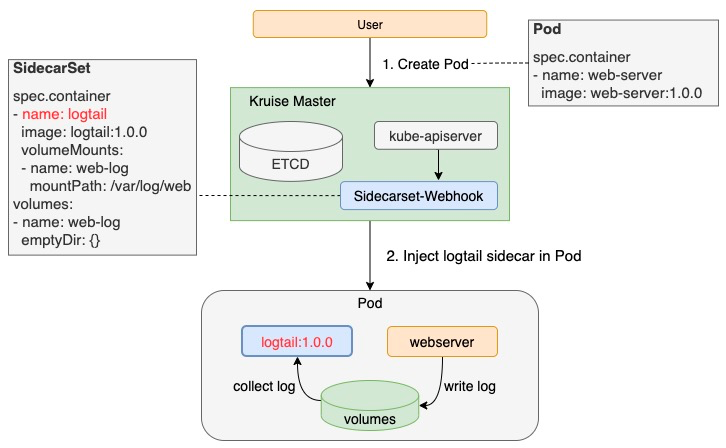
New Features of SidecarSet
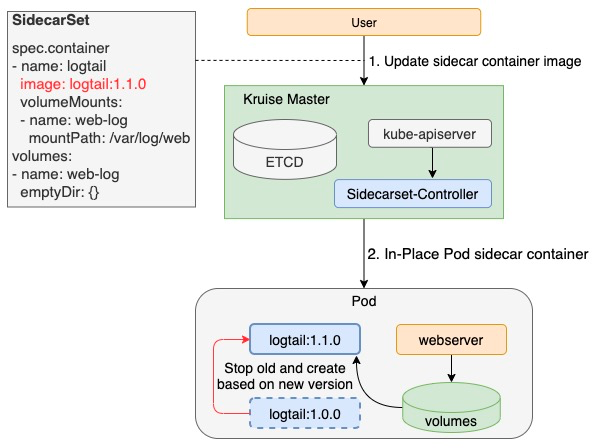
Sidecar Hot Upgrade Function
SidecarSet is a workload provided by OpenKruise to manage sidecar containers separately. Users can inject and upgrade specified sidecar containers within a certain range of Pods using SidecarSet.
By default, for the independent in-place sidecar upgrade, the sidecar stops the container of the old version first and then creates a container of the new version. This method applies to sidecar containers that do not affect the Pod service availability, such as the log collection agent. However, for sidecar containers acting as a proxy such as Istio Envoy, this upgrade method is defective. Envoy, as a proxy container in the Pod, handles all the traffic. If users restart and upgrade directly, service availability will be affected. Thus, you need a complex grace termination and coordination mechanism to upgrade the envoy sidecar separately. Therefore, we offer a new solution for the upgrade of this kind of sidecar containers, namely, hot upgrade:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
spec:
# ...
containers:
- name: nginx-sidecar
image: nginx:1.18
lifecycle:
postStart:
exec:
command:
- /bin/bash
- -c
- /usr/local/bin/nginx-agent migrate
upgradeStrategy:
upgradeType: HotUpgrade
hotUpgradeEmptyImage: empty:1.0.0
upgradeType:HotUpgradeindicates that the type of the sidecar container is a hot upgrade, so the hot upgrade solution,hotUpgradeEmptyImage, will be executed. When performing a hot upgrade on the sidecar container, an empty container is required to switch services during the upgrade. The empty container has almost the same configuration as the sidecar container, except the image address, for example, command, lifecycle, and probe, but it does no actual work.lifecycle.postStart: State migration. This procedure completes the state migration during the hot upgrade. The script needs to be executed according to business characteristics. For example, NGINX hot upgrade requires shared Listen FD and traffic reloading.
More
For more changes, please refer to the release page or ChangeLog.


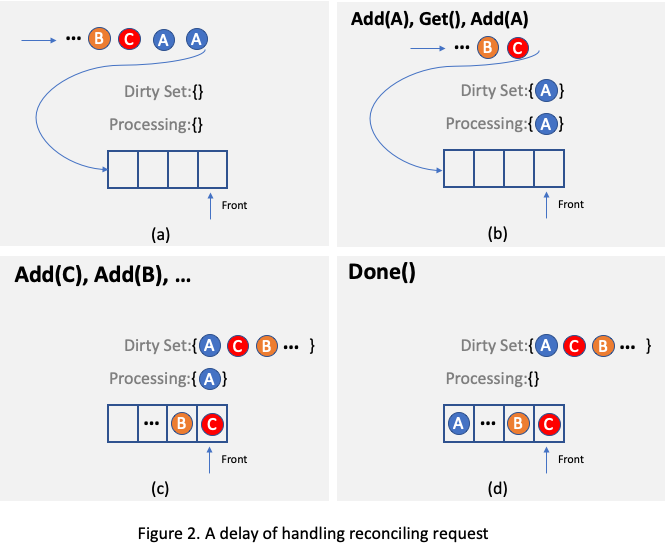 .... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the
.... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the