OpenKruise 0.8.0, A Powerful Tool for Sidecar Container Management

OpenKruise is an open source management suite developed by Alibaba Cloud for cloud native application automation. It is currently a Sandbox project hosted under the Cloud Native Computing Foundation (CNCF). Based on years of Alibaba's experience in container and cloud native technologies, OpenKruise is a Kubernetes-based standard extension component that has been widely used in the Alibaba internal production environment, together with technical concepts and best practices for large-scale Internet scenarios.
OpenKruise released v0.8.0 on March 4, 2021, with enhanced SidecarSet capabilities, especially for log management of Sidecar.
Background
Sidecar is a very important cloud native container design mode. It can create an independent Sidecar container by separating the auxiliary capabilities from the main container. In microservice architectures, the Sidecar mode is also used to separate general capabilities such as configuration management, service discovery, routing, and circuit breaking from main programs, thus making the microservice architectures less complicated. Since the popularity of Service Mesh has led to the prevalence of the Sidecar mode, the Sidecar mode has also been widely used within Alibaba Group to implement common capabilities such as O&M, security, and message-oriented middleware.
In Kubernetes clusters, pods can not only support the construction of main containers and Sidecar containers, but also many powerful workloads, such as deployment and statefulset to manage and upgrade the main containers and Sidecar containers. However, with the ever-growing businesses in Kubernetes clusters day by day, there have also been various Sidecar containers with a larger scale. Therefore, management and upgrades of online Sidecar containers are more complex:
- A business pod contains multiple Sidecar containers, such as O&M, security, and proxy containers. The business team should not only configure the main containers, but also learn to configure these Sidecar containers. This increases the workloads of the business team and the risks in Sidecar container configuration.
- The Sidecar container needs to be restarted together with the main business container after the upgrade. The Sidecar container supports hundreds of online businesses, so it is extremely difficult to coordinate and promote the upgrades of a large number of online Sidecar containers.
- If there are no effective updates for Sidecar containers with different online configurations and versions, it will pose great potential risks to the management of Sidecar containers.
Alibaba Group has millions of containers with thousands of businesses. Therefore, the management and upgrades of Sidecar containers have become a major target for improvement. To this end, many internal requirements for the Sidecar containers have been summarized and integrated into OpenKruise. Finally, these requirements were abstracted as SidecarSet, a powerful tool to manage and upgrade a wide range of Sidecar containers.
OpenKruise SidecarSet
SidecarSet is an abstracted concept for Sidecar from OpenKruise. As one of the core workloads of OpenKruise, it is used to inject and upgrade the Sidecar containers in Kubernetes clusters. SidecarSet provides a variety of features so that users can easily manage Sidecar containers. The main features are as follows:
- Separate configuration management: Each Sidecar container is configured with separate SidecarSet configuration to facilitate management.
- Automatic injection: Automatic Sidecar container injection is implemented in scenarios of Pod creation, Pod scale-out and Pod reconstruction.
- In-place upgrade: Sidecar containers can be upgraded in-place without the reconstruction of any pods, so that the main business container is not affected. In addition, a wide range of gray release policies are included.
Note: For a Pod that contains multiple container modes, the container that provides the main business logic to the external is the main container. Other containers provide auxiliary capabilities such as log collection, security, and proxy are Sidecar containers. For example, if a pod provides web capabilities outward, the nginx container that provides major web server capabilities is the main container. The logtail container is the Sidecar container that is responsible for collecting and reporting nginx logs. The SidecarSet resource abstraction in this article also solves some problems of the Sidecar containers.
Sidecar logging architectures
Application logs allow you to see the internal running status of your application. Logs are useful for debugging problems and monitoring cluster activities. After the application is containerized, the simplest and most widely used logging is to write standard output and errors.
However, in the current distributed systems and large-scale clusters, the above solution is not enough to meet the production environment standards. First, for distributed systems, logs are scattered in every single container, without a unified place for congregation. Logs may be lost in scenarios such as container crashes and Pod eviction. Therefore, there is a need for a more reliable log solution that is independent of the container lifecycle.
Sidecar logging architectures places the logging agent in an independent Sidecar container to collect container logs by sharing the log directory. Then, the logs are stored in the back-end storage of the log platform.
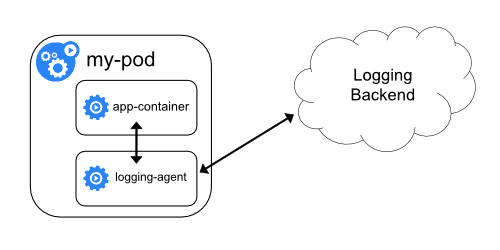
This architecture is also used by Alibaba and Ant Group to realize the log collection of containers. Next, this article will explain how OpenKruise SidecarSet helps a large-scale implementation of the Sidecar log architecture in Kubernetes clusters.
Automatic Injection
OpenKruise SidecarSet has implemented automatic Sidecar container injection based on Kubernetes AdmissionWebhook mechanism. Therefore, as long as the Sidecar is configured in SidecarSet, the defined Sidecar container will be injected into the scaled pods with any deployment patterns, such as CloneSet, Deployment, or StatefulSet.
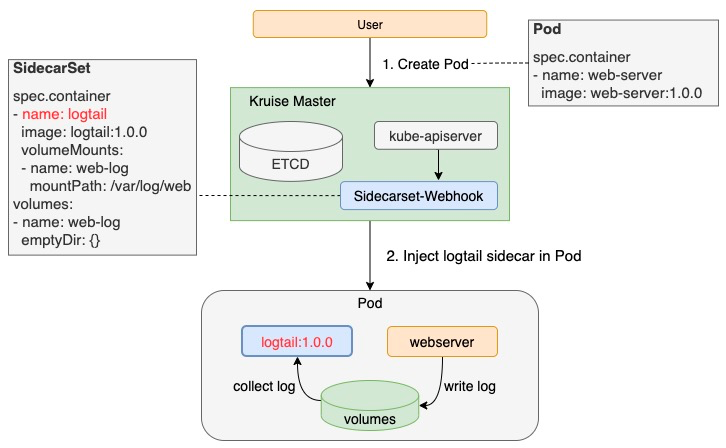
The owner of Sidecar containers only needs to configure SidecarSet to inject the Sidecar containers without affecting the business. This greatly reduces the threshold for using the Sidecar containers, and facilitates the management of Sidecar owners. In addition to containers, SidecarSet also extends the following fields to meet various scenarios of Sidecar injection:
# sidecarset.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: test-sidecarset
spec:
# Select Pods through the selector
selector:
matchLabels:
app: web-server
# Specify a namespace to take effect
namespace: ns-1
# container definition
containers:
- name: logtail
image: logtail:1.0.0
# Share the specified volume
volumeMounts:
- name: web-log
mountPath: /var/log/web
# Share all volumes
shareVolumePolicy:
type: disabled
# Share environment variables
transferEnv:
- sourceContainerName: web-server
envName: TZ
volumes:
- name: web-log
emptyDir: {}
Pod selector
- The selector is supported to select the pods to be injected. In the above example, the pod of labels[app] = web-server is selected to inject the logtail container. Alternatively, labels[inject/logtail] = true can be added in all pods to inject a global Sidecar.
- namespace: SidecarSet is globally valid by default. This parameter can be configured to make it valid to a specific namespace.
Data volume sharing
- Share the specified volume: Use volumeMounts and volumes to share a specified volume with the main container. In the above example, a web-log volume is shared to achieve log collection.
- Share all volumes: Use shareVolumePolicy = enabled | disabled to specify whether to mount all volumes in the Pod's main container, which is often used for Sidecar containers such as log collection. If the configuration is enabled, all mount points in the application container are injected into the same Sidecar path, unless there are data volumes and mount points declared by Sidecar.)
Share environment variables
Use transferEnv to obtain environment variables from other containers, which copies the environment variable named envName in the sourceContainerName container to the current Sidecar container. In the above example, the Sidecar container of logs shares the time zone of the main container, which is especially common in overseas environments.
Note: The number of containers for the created Pods cannot be changed in the Kubernetes community. Therefore, the injection capability described above can only occur during the Pod creation phase. For the created Pods, Pod reconstruction is required for injection.
In-place Upgrade
SidecarSet not only allows to inject the Sidecar containers, but also reuses the in-place update feature of OpenKruise. This realizes the upgrade of the Sidecar containers without restarting the Pod and the main container. Since this upgrade method does not affect the business, upgrading the Sidecar containers is no longer a pain point. Thus, it brings a lot of conveniences to Sidecar owners and speeds up the Sidecar version iteration.
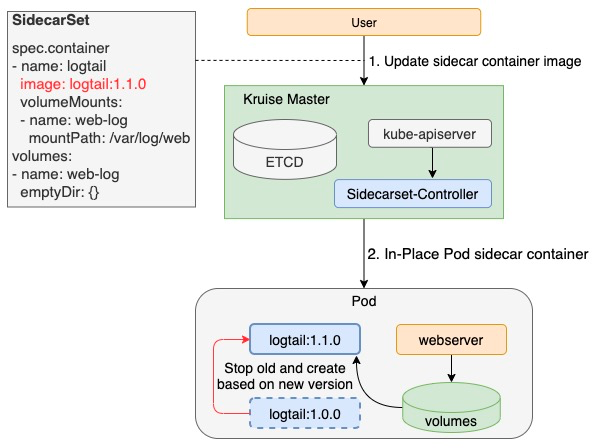
Note: Only the modification on the container.image fields for the created Pods is allowed by the Kubernetes community. Therefore, the modification on other fields of Sidecar containers requires the reconstruction of Pod, and the in-place upgrade is not supported.
To meet the requirements in some complex Sidecar upgrade scenarios, SidecarSet provides the in-place upgrade and a wide range of gray release strategies.
Gray Release
Gray release is a common method that allows a Sidecar container to be released smoothly. It is highly recommended that this method is used in large-scale clusters. Here is an example of Pod's rolling release based on the maximum unavailability after the first batch of Pod release is suspended. Suppose that there are 1,000 Pods to be released:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
partition: 980
maxUnavailable: 10%
The configuration above is suspended after the former release of 20 pods (1000 – 980 = 20). After the Sidecar container has been normal for a period of time in business, adjust the update SidecarSet configuration:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
maxUnavailable: 10%
As such, the remaining 980 Pods will be released in the order of the maximum unavailable numbers (10% * 1000=100) until all Pods are released.
Partition indicates that the number or percentage of Pods of the old version is retained, with the default value of 0. Here, the partition does not represent any order number. If the partition is set up during the release process:
- If it is a number, the controller will update the pods with (replicas – partition) to the latest version.
- If it is a percentage, the controller will update the pods with (replicas * (100% - partition)) to the latest version.
MaxUnavailable indicates the maximum unavailable number of pods at the same time during the release, with the default value of 1. Users can set the MaxUnavailable value as absolute value or percentage. The percentage is used by the controller to calculate the absolute value based on the number of selected pods.
Note: The values of maxUnavailable and partition are not necessarily associated. For example:
- Under {matched pod} = 100, partition = 50, and maxUnavailable = 10, the controller will release 50 pods to the new version, but the release is limited to 10. That is, only 10 pods are released at the same time. A pod is released one after another until 50 pods are all released.
- Under {matched pod} = 100, partition = 80, and maxUnavailable = 30, the controller will release 20 Pods to the new version. The controller releases all 20 pods at the same time because the number of maxUnavailable is met.
Canary Release
For businesses that require canary release, strategy.selector can be considered as a choice. The solution is to mark the labels[canary.release] = true into the Pods that require canary release, and then use strategy.selector.matchLabels to select the pods.
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
canary.release: "true"
maxUnavailable: 10%
The above configuration only releases the containers marked with canary labels. After the canary verification is completed, rolling release is performed based on the maximum unavailability by removing the configuration of updateStrategy.selector.
Scatter Release
The upgrade sequence of pods in SidecarSet is subject to the following rules by default:
- For the pod set upgrade, multiple upgrades with the same order are guaranteed.
- The selection priority is (the smaller, the more prioritized): unscheduled < scheduled, pending < unknown < running, not-ready < ready, newer pods < older pods.
In addition to the above default release order, the scatter release policy allows users to scatter the pods that match certain labels to the entire release process. For example, for a global sidecar container like logtail, dozens of business pods may be injected into a cluster. Thus, the logtail can be released after being scattered based on the application name, realizing scattered and gray release among applications. And it can be performed together with the maximum unavailability.
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
scatterStrategy:
- key: app_name
value: nginx
- key: app_name
value: web-server
- key: app_name
value: api-gateway
maxUnavailable: 10%
Note: In the current version, all application names must be listed. In the next version, an intelligent scattered release will be supported with only the label key configured.
Summary
In the OpenKruise v0.8.0, the SidecarSet has been improved in terms of log management in Sidecar scenarios. In the later exploration of the stability and performance of SidecarSet, more scenarios will be covered at the same time. For example, Service Mesh scenario will be supported in the next version. Moreover, more people are welcomed to participate OpenKruise community to improve the application management and delivery extensibility of Kubernetes for scenarios featuring large scale, complexity and extreme performance.

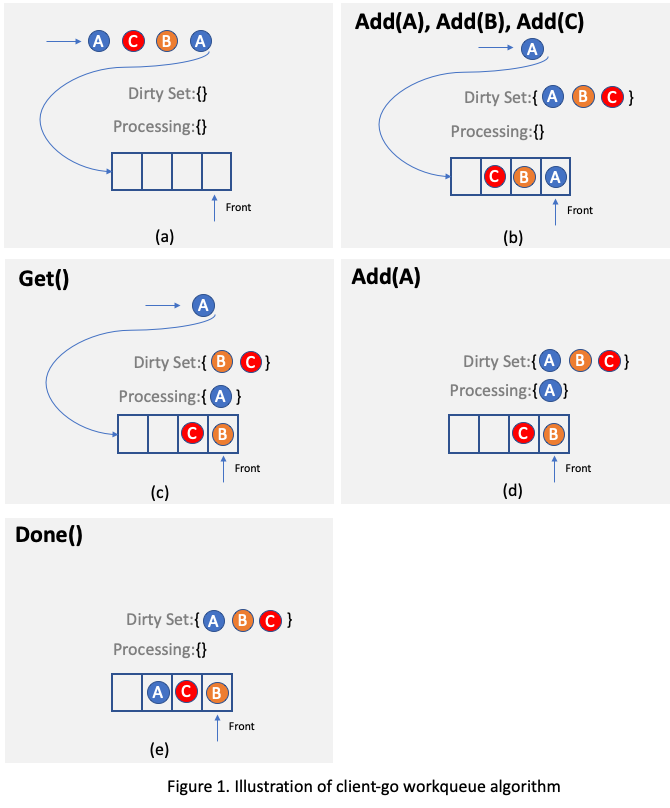
 .... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the
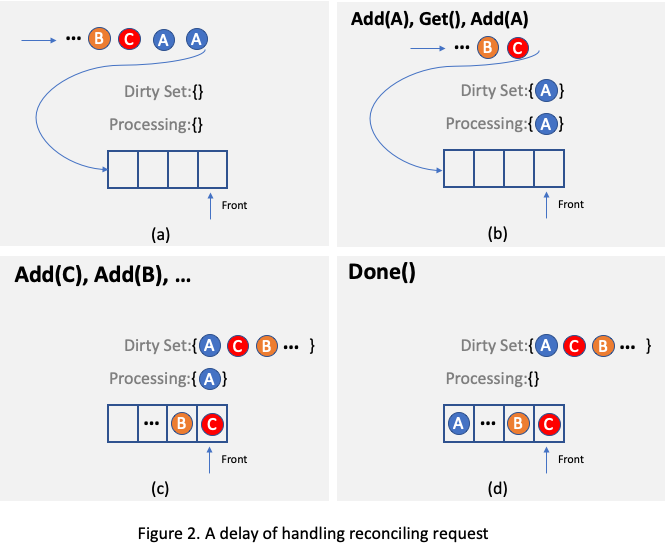
.... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the 