OpenKruise Agents v0.3.0: Making Agent Sandboxes Truly Operatable
Keywords: Batch Upgrade · Multi-Tenancy · In-Place VPA · Lifecycle Hook · E2B Compatible
As AI Agents move into large-scale production, Sandboxes — the runtime containers that host tool invocations, code interpreters, and long-running session workspaces — have rapidly evolved from "just make it work" to "make it fast, stable, and manageable." In 2025, the CNCF workload project OpenKruise incubated a sub-project dedicated to Agent scenarios — OpenKruise Agents, focused on solving delivery efficiency, resource governance, and operational challenges for AI Agent workloads on Kubernetes.
Recently, OpenKruise Agents officially released v0.3.0. This release brings significant enhancements across three dimensions: upgrade operations, multi-tenant governance, and cost optimization. The three most anticipated core features are: a complete upgrade pipeline for warm pool and claimed Sandboxes (SandboxUpdateOps batch upgrade CR + Recreate strategy + Lifecycle Hooks), a multi-tenant isolation and authorization system based on Teams and API Keys, and in-place CPU resizing (VPA) during the Claim phase.
This post is organized in two parts: Part One covers the overall positioning and core concepts of OpenKruise Agents to help newcomers get up to speed; Part Two dives into the three core features of v0.3.0 with YAML examples and scenario breakdowns, explaining their design motivation, mechanics, and usage.
Part One: What Is OpenKruise Agents and What Can It Do
1.1 Project Positioning
OpenKruise Agents provides best practices for managing AI agent workloads in Kubernetes.
OpenKruise Agents is an extension of OpenKruise for AI Agent scenarios, providing cloud-native workload abstractions and runtime governance for "sandboxed" agent workloads.
It is neither an Agent framework nor an LLM inference engine, but rather the "workload layer" for sandboxes themselves — bringing scenarios like E2B, AgentScope, Manus, OpenClaw, and Code Interpreter that require per-session/task isolated environments down to Kubernetes for unified scheduling, lifecycle management, and interface exposure. Its design goals cover four typical workload categories:
- Isolated execution environments for diverse AI Agent tool invocations (Code Interpreter, Shell, Browser, etc.);
- Network-accessible, persistent cloud development workspaces for Research Notebooks / Codespaces;
- High-concurrency tasks in reinforcement learning for Human-in-the-loop and Open-world training;
- Fast startup and fault recovery requirements for large-scale training tasks.
1.2 Key Capabilities Overview
The core value of OpenKruise Agents can be summarized in four pillars:
First, ultra-fast delivery through resource pooling and dynamic scaling. By pre-creating a batch of idle Sandboxes in a Warm Pool, when an Agent request arrives it simply "claims" one from the pool, eliminating Pod startup time from the delivery path and achieving sub-second cold starts.
Second, Hibernation and Checkpointing. Sandboxes can be paused when idle to release CPU/memory, then resumed on demand; the Checkpoint CRD can take memory + filesystem snapshots of running Sandboxes and fork multiple identical replicas from them — essential for RL rollouts, debugging reproduction, and similar scenarios. (Note: This feature is currently available on Alibaba Cloud ACS; the open-source community version is being gradually released.)
Third, user identity, Teams, and traffic routing. Each Sandbox is not a bare Pod but a "user-level runtime" with Team / API Key isolation and efficient traffic proxying. This layer minimizes dependence on Kubernetes Services (which are not flexible enough and have quantity limits in sandbox scenarios).
Fourth, dual-protocol APIs. OpenKruise Agents provides both a Kubernetes CRD API (for platform engineers / SREs) and a fully E2B-compatible API (for ML engineers / upstream Agent frameworks). Teams already using the E2B SDK can connect to an OpenKruise Agents backend with zero code changes.
1.3 Core Concept Map
Understanding OpenKruise Agents requires clarifying the relationships between several CRDs:
| CRD | Short Name | Role |
|---|---|---|
Sandbox | sbx | Core resource representing a specific sandbox instance (typically backed by a Pod), supporting advanced lifecycle operations such as Create/Delete/Pause/Resume/Lifecycle |
SandboxSet | sbs | Workload that manages a batch of homogeneous Sandboxes (analogous to ReplicaSet for Pods), primarily responsible for maintaining the warm pool and serving as the Sandbox template |
SandboxTemplate | — | Immutable template version snapshot. SandboxSet derives a SandboxTemplate when the template changes, used for version tracing |
SandboxClaim | sbc | A "claim request" issued against a SandboxSet — claims an unused Sandbox from the warm pool and performs post-processing such as in-place image replacement, dynamic storage mounting, and in-place VPA CPU resizing |
Checkpoint | cp | Runtime state snapshot of a Sandbox (memory + rootfs), which can be used to fork multiple new instances |
SandboxUpdateOps | suo | New in v0.3.0, batch upgrade operations targeting "claimed" Sandboxes |
The data flow connects as follows: Platform administrators define a SandboxSet → the controller maintains a certain number of Sandboxes in available state within the warm pool → Agents claim Sandboxes via the E2B SDK or SandboxClaim CR → claimed Sandboxes can be Paused/Resumed, Checkpointed, or upgraded via SandboxUpdateOps, and are eventually reclaimed upon completion or timeout.
1.4 Architecture Overview
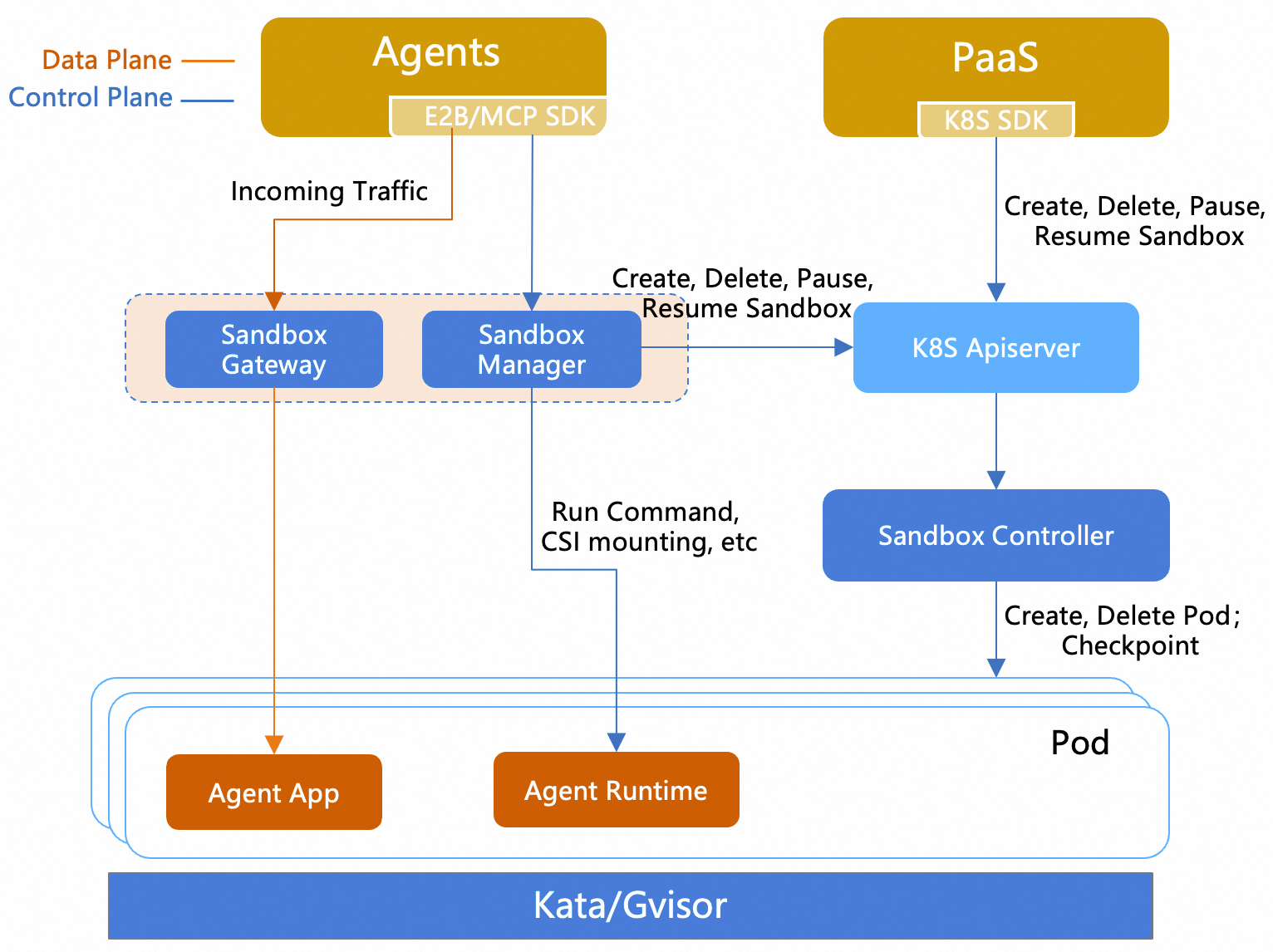
OpenKruise Agents has a clear separation between the control plane and data plane, consisting of four components:
- sandbox-manager: A stateless backend service that exposes E2B API and MCP API externally, serving as the entry point for SDKs and external Agent frameworks;
- sandbox-gateway: A lightweight gateway built on Envoy filters that precisely routes inbound traffic to specific Pods by namespace + sandbox name + port, minimizing dependence on K8s Services;
- sandbox-controller: A set of controllers responsible for reconciling CRDs such as SandboxSet / SandboxClaim / SandboxUpdateOps, and hosting related admission webhooks;
- agent-runtime: Injected as a sidecar into Sandbox Pods, providing E2B envd-compatible command and file operations, dynamic CSI mounting, Lifecycle Hook script execution, and other runtime capabilities.
This layered design enables OpenKruise Agents to seamlessly integrate with the E2B ecosystem "upward" while fully leveraging native K8s workload capabilities "downward" (rolling updates, Pod topology awareness, PVC, CSI, etc.).
1.5 Relationship with E2B
E2B is the most widely used open-source Sandbox SDK in the AI Agent space, offering Python / JavaScript clients. The sandbox-manager in OpenKruise Agents supports both the native E2B protocol and extended protocols:
from e2b_code_interpreter import Sandbox
# Standard E2B usage — runs on OpenKruise Agents cluster with zero modifications
with Sandbox.create(template="demo") as sbx:
print(sbx.get_info())
# Use OpenKruise Agents enhanced capabilities via extended metadata
sbx = Sandbox.create(template="demo", metadata={
# In-place image replacement: replace the default warm pool image with a specific version at claim time
"e2b.agents.kruise.io/image": "my-registry/sandbox:v2",
# In-place CPU resizing (VPA): adjust resources on demand without Pod recreation
"e2b.agents.kruise.io/cpu-request": "2000m",
"e2b.agents.kruise.io/cpu-limit": "4",
# Dynamic storage mounting: automatically mount persistent volumes at claim time
"e2b.agents.kruise.io/csi-volume-config": '[{"pvName":"nas-pv-sandbox-system","mountPath":"/data-nas","subPath":"data-subPath"},{...}]',
})
Here, template="demo" corresponds to a SandboxSet named demo. Standard E2B code runs without any modifications; through e2b.agents.kruise.io/* extended metadata, image replacement, resource resizing, and storage mounting can all be completed in a single claim operation without additional API calls.
In other words, OpenKruise Agents embraces E2B's application semantics while transforming the underlying infrastructure into workloads that K8s platform teams can govern. Teams with existing E2B code get a near drop-in replacement; platform teams gain the full cloud-native toolchain including rolling upgrades, Quotas, Sidecar injection, and dynamic PV mounting.
Part Two: v0.3.0 Key Features: Upgrade Operations, Cost Optimization, and Multi-Tenant Governance
If previous versions addressed "how to deliver Sandboxes quickly," then the core theme of v0.3.0 is "after delivery, how to manage, use, and upgrade them well" — batch upgrades make Sandbox versions controllable and convergent, VPA enables on-demand resource allocation without waste, and multi-tenancy brings clear accountability to shared clusters.
2.1 Background: Why Upgrading Claimed Sandboxes Is So Hard
A cluster typically contains two types of Sandboxes simultaneously:
- Unassigned Sandboxes: Idle instances residing in the SandboxSet warm pool that have not yet been claimed;
- Claimed Sandboxes: Active instances that have been claimed by Agents and are carrying user sessions or long-running tasks.
Upgrading the former is straightforward — modify the SandboxSet's spec.template and the controller performs a rolling replacement based on maxUnavailable. The real challenge lies with the latter:
- These Sandboxes carry user state (workspace files, model caches, long session contexts) and cannot be simply
kubectl delete pod'd; - They are managed directly by the Sandbox CRD, not belonging to any ReplicaSet/Deployment, and native K8s lacks a mechanism to "batch upgrade a set of independent Sandboxes";
- Upgrades inevitably involve Pod recreation (changing images, resources, volumes, etc.), meaning IP changes, in-memory state loss, and rootfs writable layer loss — the application layer needs explicit hook points to perform "backup → recreate → restore."
v0.3.0 delivers two complementary features for upgrade operations: SandboxUpdateOps batch upgrade CR and Recreate strategy + Lifecycle Hooks.
2.2 SandboxUpdateOps: Batch Upgrade CR for Claimed Sandboxes
SandboxUpdateOps (short name suo) is a new CRD introduced in v0.3.0 with a clear purpose: dispatch upgrade tasks to a batch of claimed, running Sandboxes in one shot.
Design Model
Comparable to a Kubernetes Job — one-time, with a well-defined target set and terminal state. It consists of three core configuration blocks:
selector: Selects the target Sandbox set via Labels (supportingmatchLabels/matchExpressions), typically batch-selecting a category of Sandboxes by theagents.kruise.io/sandbox-template=<sandboxset-name>label;updateStrategy.maxUnavailable: The maximum number of Sandboxes that can be upgrading simultaneously, supporting absolute values or percentages, defaulting to 1 — this is the core knob for canary upgrades;patch: Applied to each Sandbox'sspec.templateas a Strategic Merge Patch, carrying the change payload — can replace images, add/remove Volumes, adjust environment variables, etc.
Minimal working example:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxUpdateOps
metadata:
name: upgrade-my-sandboxes
namespace: default
spec:
selector:
matchLabels:
agents.kruise.io/sandbox-template: my-sandbox-pool
updateStrategy:
maxUnavailable: 2
patch:
spec:
containers:
- name: sandbox
image: my-registry/sandbox-image:v2
Key Constraints
- Only one
UpdatingSandboxUpdateOps is allowed per Namespace at a time — to prevent interference between multiple tasks, a new one can only be initiated after the previous one completes or is deleted; - Only upgrades Sandboxes with
PhaseofRunningorUpgrading; hibernating or waking instances are not supported; - SandboxUpdateOps is a one-time task — if it fails, it must be deleted and recreated (consistent with Job semantics);
- Only applicable to Claimed Sandboxes; unassigned Sandboxes in the warm pool follow the SandboxSet's
updateStrategy.
Observability and Status
Upgrade progress can be viewed intuitively via kubectl get suo:
NAME PHASE TOTAL UPDATED UPDATING FAILED AGE
upgrade-my-sandboxes Updating 1000 66 100 0 2m32s
PHASE:Pending/Updating/Completed/FailedTOTAL: Total number of Sandboxes selected by the selectorUPDATED: Number of successfully upgraded SandboxesUPDATING: Number currently being upgraded (bounded bymaxUnavailable)FAILED: Number of failed upgrades
Each upgraded Sandbox is labeled with agents.kruise.io/update-ops=<suo-name> for easy filtering by UpdateOps:
kubectl get sandbox -l agents.kruise.io/update-ops=upgrade-my-sandboxes
2.3 Recreate Upgrade Strategy + Lifecycle Hooks: Preserving Data Through Pod-Recreating Upgrades
SandboxUpdateOps is the "task orchestration layer," while Recreate strategy + Lifecycle Hooks form the "execution layer" for individual Sandbox upgrades. Together, they constitute the core of the v0.3.0 upgrade pipeline.
Upgrade Flow
As shown in the diagram below, the Recreate strategy breaks down a single Sandbox upgrade into three strictly sequential phases: PreUpgrade (run backup scripts to write data to OSS / NAS) → UpgradePod (delete the old Pod and recreate with the new template) → PostUpgrade (restore data from external storage). Any phase failure halts the process and transitions to the corresponding Failed state.
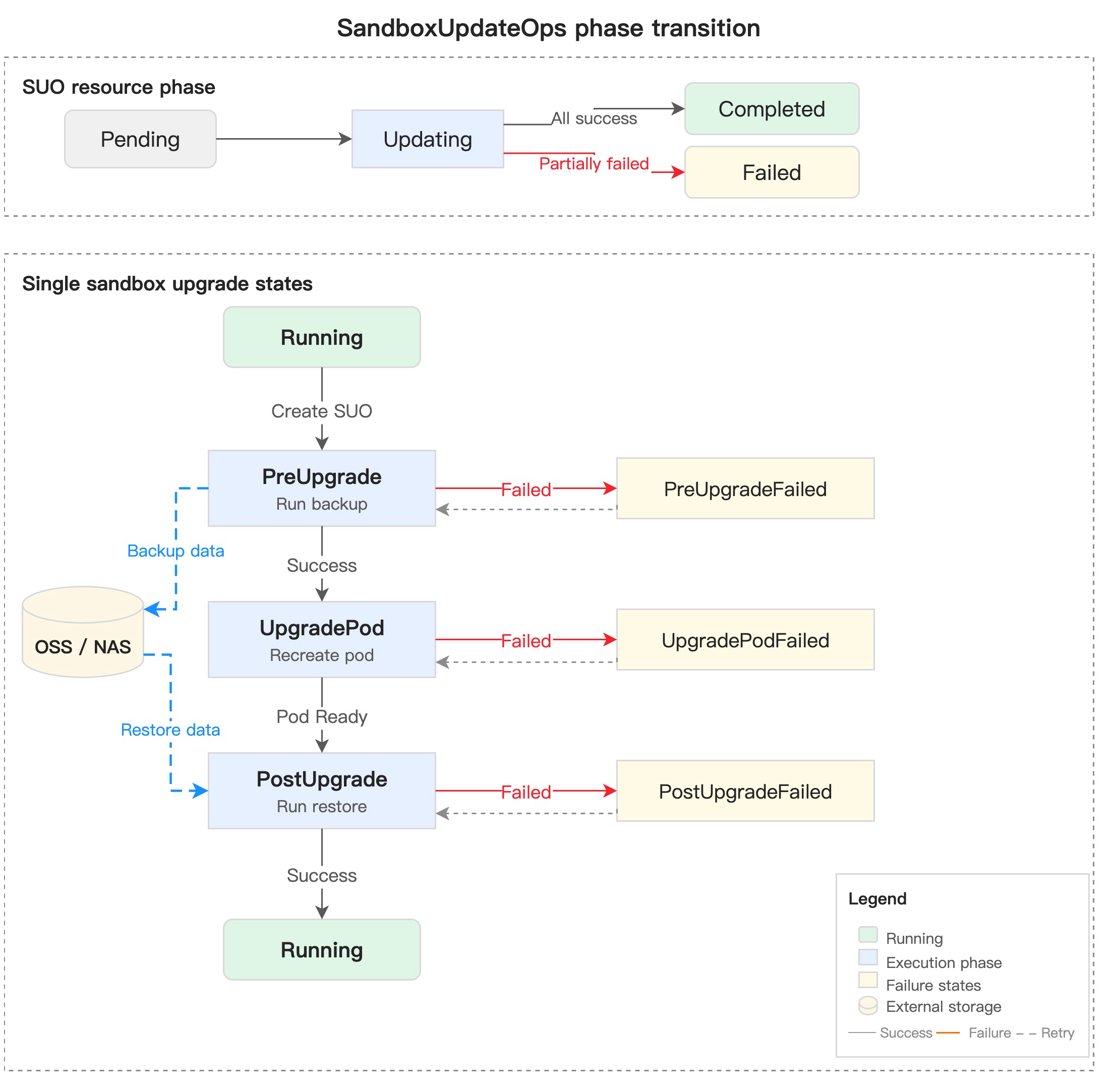
The strategy is called Recreate because the upgrade path must recreate the underlying Pod (changing images, resources, or mounts cannot be done purely in-place). Pod recreation means IP changes, in-memory state wipe, and rootfs writable layer loss — so OpenKruise Agents provides a hook before and after the recreation, allowing users to handle data backup and restoration themselves.
preUpgrade / postUpgrade Hooks
preUpgrade: Executed before the old Pod is destroyed. Typical use: package and back up the working directory, long session contexts, model caches, etc. to persistent storage like OSS / NAS;postUpgrade: Executed after the new Pod is Ready. Typical use: restore backup data from persistent storage to the working directory.
Hook execution depends on two sidecars:
- agent-runtime: Provides E2B envd-compatible command execution capability; all Hook scripts ultimately run inside the Sandbox through it;
- csi: Dynamic mounting capability; must be injected if backup/restore needs to write to OSS / NAS.
Here is a complete example — packaging the OpenClaw workspace .openclaw to a dynamically mounted OSS directory /backup before upgrade, and restoring it afterward:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxUpdateOps
metadata:
name: upgrade-with-backup
namespace: default
spec:
selector:
matchLabels:
agents.kruise.io/sandbox-template: openclaw-sbs
updateStrategy:
maxUnavailable: 10%
patch:
spec:
containers:
- name: gateway
image: ghcr.io/openclaw/openclaw:2026.4.11 # New version image
lifecycle:
preUpgrade:
exec:
command:
- /bin/bash
- -c
- |
set -e
cd /root/
tar -czf openclaw-state-v1.tgz .openclaw
mv openclaw-state-v1.tgz /backup
echo 'preUpgrade success'
timeoutSeconds: 600
postUpgrade:
exec:
command:
- /bin/bash
- -c
- |
set -e
rm -rf /root/.openclaw
cp /backup/openclaw-state-v1.tgz /root/openclaw-state-v1.tgz
tar -xzvf /root/openclaw-state-v1.tgz -C /root
rm -rf /root/openclaw-state-v1.tgz
timeoutSeconds: 600
Fine-Grained State Machine: Pinpointing Each Sandbox's Failure Point
During the upgrade process, a Sandbox is in Phase=Upgrading, with the current stage exposed via status.conditions[type=Upgrading].reason:
| Reason | Description |
|---|---|
PreUpgrade | Executing the preUpgrade script |
PreUpgradeFailed | preUpgrade script execution failed |
UpgradePod | Recreating the Pod with the new template |
UpgradePodFailed | New Pod startup failed (image pull failure, startup timeout, crash, etc.) |
PostUpgrade | Executing the postUpgrade script |
PostUpgradeFailed | postUpgrade script execution failed |
Succeeded | Upgrade completed |
This design makes troubleshooting highly intuitive — kubectl get sandbox <name> -o yaml to inspect conditions immediately reveals which stage is stuck and the specific error message. Remediation strategies after failure:
- PreUpgrade failure: The underlying container is untouched; data is safe. Fix the script or rollback the patch;
- UpgradePod failure: The old Pod has been destroyed but the new Pod is not up. Use Checkpoint to recover, or rollback the patch to the old image. Note that preUpgrade has already executed at this point; when retrying, you must remove preUpgrade to avoid duplicate backups;
- PostUpgrade failure: The new Pod is ready but the restore script failed. Fix the script and create a new SandboxUpdateOps with only
postUpgradeto retry.
Pausing an In-Progress Upgrade
If issues are discovered during an upgrade and you need to "hit the brakes," simply set paused: true:
spec:
paused: true
This only prevents new Sandboxes from entering the upgrade queue; Sandboxes already being upgraded will continue through their existing workflow.
2.4 In-Place CPU Resize: Pre-warm at Minimal Specs, Scale Up On Demand at Claim Time
Problem Statement
The core value of the warm pool is "fast startup" — pre-creating Sandboxes so that when a request arrives, it can be claimed immediately, bypassing Pod startup time. From a cost perspective, the warm pool should use minimal specs (e.g., 0.5C1G) to reduce idle resource consumption. However, in practice, different Agent tasks have vastly different resource requirements — data analysis may need 4 cores, while local LLM inference may require 8 cores.
Previous approaches each had drawbacks: maintaining a separate SandboxSet for each spec tier (scattered pools, management complexity); pre-warming uniformly at the maximum spec (severe resource waste when idle); recreating Pods to adjust specs after claiming (completely negating the warm pool advantage).
v0.3.0 leverages native Kubernetes In-Place Pod Vertical Scaling to perform "in-place resizing" on warm pool Sandboxes during the Claim phase — no Pod recreation, no IP change, no container restart, only CPU requests/limits are adjusted. This preserves the warm pool's sub-second delivery while satisfying the need for differentiated on-demand configuration.
Usage: Dual-Protocol via E2B and SandboxClaim
Via E2B SDK (using extended metadata):
from e2b_code_interpreter import Sandbox
sbx = Sandbox.create(template="demo", metadata={
"e2b.agents.kruise.io/cpu-request": "1000m",
"e2b.agents.kruise.io/cpu-limit": "2"
})
Via SandboxClaim CR declaratively:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxClaim
metadata:
name: demo-sandbox-claim
namespace: default
spec:
templateName: demo
inplaceUpdate:
resources:
requests:
cpu: "1000m"
limits:
cpu: "2"
Usage Constraints
- Currently only CPU resize is supported; memory and other resources are ignored;
- Only applies to the main container (sidecars are unchanged);
- Resizing must not change the Pod's QoS class (e.g., downgrading from Guaranteed to Burstable will be rejected);
- Requires Kubernetes in-place pod resize — K8s 1.33+ is recommended (the feature is beta and enabled by default); K8s 1.27–1.32 requires manually enabling the
InPlacePodVerticalScalingfeature gate; - This capability is controlled by the
SandboxInPlaceResourceResizefeature gate, which is enabled by default on the OpenKruise Agents side; - Can be combined with image replacement at claim time (
inplaceUpdate.image) — swap images and resize resources in a single claim.
2.5 Team-Based Multi-Tenant Isolation and API Key Authorization
v0.3.0 introduces a complete multi-tenant authorization model, providing clear isolation boundaries for multi-team shared clusters in production environments.
Core design: Team Name = Kubernetes Namespace. Each Team's identity is uniquely identified by its Team Name, which maps directly to an existing Kubernetes Namespace. This means the Namespace's inherent isolation naturally becomes the Sandbox's authorization boundary — no additional isolation abstractions needed; tenants can only operate on resources within their own Namespace.
Two-level role model:
| Role | Scope |
|---|---|
Admin (admin Team) | Cluster-level permissions: issue/revoke API Keys for any Team, view all Teams and Sandboxes |
| Regular Tenant | Namespace-level permissions: manage their own Team's Keys, can only access Sandboxes created by their own Keys |
The built-in admin API Key is initialized when sandbox-manager starts and cannot be deleted for cluster controllability.
API Key as identity credential. When clients call any sandbox-manager endpoint, they carry credentials via the X-API-KEY request header. An API Key determines three things: which Team the caller belongs to, whether they are an admin, and which Sandboxes they can access. sandbox-manager provides a set of E2B-compatible HTTP endpoints (GET/POST/DELETE /api-keys, GET /teams) for full Key lifecycle management.
Pluggable Key storage backends. API Key persistence supports two backends, switched via the --e2b-key-storage parameter:
secret(default): A zero-dependency approach that stores all Keys in a Kubernetes Secret, suitable for trials or single-tenant scenarios (recommended Key count ≤ 500);mysql: Persists to MySQL via GORM, storing only HMAC-SHA256 hashes, never plaintext. Suitable for multi-tenant, multi-replica production deployments with shared Key storage and no capacity bottleneck.
A typical multi-tenant workflow: Cluster admin uses the admin Key to issue the first API Key for each Team → tenants use their own Key to self-service create additional Keys (e.g., a CI Runner-specific Key) → tenants create and manage Sandboxes within their own Namespace via Keys → admins can globally observe and govern resource usage across all Teams.
Part Three: Roadmap and Community
With v0.3.0 completing the "upgrade operations" puzzle, the community's next phase will focus on:
- Traffic Management and Security Policies (#433): Introducing
TrafficPolicy/GlobalTrafficPolicy(L3/L4) andSecurityProfile(L7) CRDs to provide fine-grained egress traffic control for Sandboxes — supporting IP/port-level allow-deny rules, as well as L7 policies based on HTTP host/path/method (interception, rate limiting, identity injection, traffic mirroring, etc.); - Security Identity Integration (Proposal): Introducing a pluggable Gateway Identity Provider framework that, when Sandboxes access external services through the gateway, issues access tokens bound to the Sandbox/Agent from an external identity service and automatically performs credential substitution at the gateway layer — supporting automatic token refresh, mTLS authentication, and graceful degradation (falling back to UUID tokens when the identity service is unavailable to avoid blocking delivery);
If you are building an AI Agent platform, Code Interpreter service, long-session Codespace, reinforcement learning training framework, or looking for a cloud-native foundation for your team's E2B deployment, feel free to star openkruise/agents, and join the community through:
- GitHub: https://github.com/openkruise/agents
- Slack: Kubernetes Slack #openkruise channel
- DingTalk Group: Search for group number
23330762 - WeChat: Add
openkruiseto be invited by the bot - Bi-weekly community meeting (Chinese): Every Thursday 19:30 GMT+8
OpenKruise Agents v0.3.0 is now available on GitHub Releases and major container registries. We look forward to your feedback and Pull Requests.