OpenKruise Agents v0.3.0 发布:让 Agent Sandbox 真正"可运维"
关键词:批量升级 · 多租户隔离 · 原地 VPA · Lifecycle Hook · E2B 兼容
随着 AI Agent 进入规模化落地阶段,Sandbox(智能体沙箱)作为承载工具调用、代码解释器、长会话工作空间的运行时容器,已从早期"能跑起来"快速演进到"要跑得快、跑得稳、还要管得住"。CNCF 工作负载项目 OpenKruise 在 2025 年孵化了面向 Agent 场景的子项目 —— OpenKruise Agents,专注解决 AI Agent 工作负载在 Kubernetes 上的交付效率、资源治理与运维难题。
近日,OpenKruise Agents 正式发布 v0.3.0 版本。本次版本在升级运维、多租户治理、成本优化三个方向均有显著增强,社区最关注的三项核心特性是:面向预热池与 Claimed Sandbox 的完整升级链路(SandboxUpdateOps 批量升级 CR + Recreate 策略 + Lifecycle Hook)、基于 Team / API Key 的多租户隔离与授权体系、以及 Claim 阶段的原地 CPU 变配(VPA)。
本文分两部分展开:第一部分盘点 OpenKruise Agents 的整体定位与核心概念,帮助首次接触的读者快速建立认知;第二部分详细介绍 v0.3.0 的三项核心特性,结合 YAML 示例和场景拆解,阐明其设计动机、工作原理和使用方式。
一、整体认知:OpenKruise Agents 是什么、能做什么
1.1 项目定位
OpenKruise Agents provides best practices for managing AI agent workloads in Kubernetes.
OpenKruise Agents 是 OpenKruise 在 AI Agent 场景下的扩展,为"沙箱化"的智能体工作负载提供云原生的工作负载抽象和运行时治理。
它既不是 Agent 框架,也不是 LLM 推理引擎,而是沙箱本身的"工作负载层"——将 E2B、AgentScope、Manus、OpenClaw、Code Interpreter 这类需要为每个会话/任务隔离环境的 Agent 场景,下沉到 Kubernetes 上做统一调度、生命周期管理和接口暴露。其设计目标覆盖四类典型工作负载:
- 为 AI Agent 多样化工具调用提供隔离执行环境(Code Interpreter、Shell、Browser 等);
- 面向 Research Notebook / Codespace 的网络可达、持久化云端开发工作空间;
- 强化学习中 Human-in-the-loop、Open-world 训练的高并发任务;
- 大数据训练任务对快速启动与容错恢复的要求。
1.2 关键能力一览
OpenKruise Agents 的核心价值可归纳为四条主线:
第一,资源池化 + 动态缩放带来的极速交付。 通过预热池(Warm Pool)预先创建一批 idle 状态的 Sandbox,Agent 请求到达时直接从池中"认领",将 Pod 启动耗时从交付链路中抹掉,实现亚秒级(sub-second)冷启动。
第二,休眠(Hibernation)与快照(Checkpoint)。 Sandbox 在空闲时可被暂停(Pause)以释放 CPU/内存,需要时再 Resume 拉起;Checkpoint CRD 可对运行中 Sandbox 做 memory + filesystem 快照,并基于该快照 Fork 出多个一模一样的副本——这在 RL rollout、调试复现等场景不可或缺。(注:该特性目前已在阿里云 ACS 上实现,社区开源版本正在逐步开放中。)
第三,用户身份、Team 与流量路由。 每个 Sandbox 对外不是裸 Pod,而是带 Team / API Key 隔离和高效流量代理的"用户级运行时"。这一层最小化了对 Kubernetes Service 的依赖(K8s Service 在沙箱场景下不够灵活且数量受限)。
第四,双协议 API。 既提供 Kubernetes CRD API(面向平台工程师 / SRE),又提供完整的 E2B 协议兼容 API(面向算法工程师 / 上层 Agent 框架)。已在使用 E2B SDK 的团队可零代码改动直接接入 OpenKruise Agents 后端。
1.3 核心概念地图
理解 OpenKruise Agents 需要先厘清几个 CRD 之间的关系:
| CRD | 短名 | 角色定位 |
|---|---|---|
Sandbox | sbx | 核心资源,代表一个具体的沙箱实例(背后通常对应一个 Pod),承载 Create/Delete/Pause/Resume/Lifecycle 等高级生命周期操作 |
SandboxSet | sbs | 管理一批同构 Sandbox 的工作负载(类比 ReplicaSet 之于 Pod),核心职责是维护预热池和作为 Sandbox 模板 |
SandboxTemplate | — | 不可变的模板版本快照。SandboxSet 在 template 变更时会派生 SandboxTemplate,用于版本追溯 |
SandboxClaim | sbc | 用户对 SandboxSet 发起的"领取请求"——从预热池中认领一个未使用的 Sandbox,并完成 原地变更镜像、动态存储挂载、原地VPA CPU等后置处理 |
Checkpoint | cp | Sandbox 的运行时状态快照(memory + rootfs),可用于 Fork 出多个新实例 |
SandboxUpdateOps | suo | v0.3.0 新增,面向"已被认领"的 Sandbox 批量执行升级操作 |
数据流串联如下:平台管理员定义 SandboxSet → 控制器维护一定数量的 Sandbox 在预热池中处于 available 状态 → Agent 通过 E2B SDK 或 SandboxClaim CR 认领 Sandbox → 认领后的 Sandbox 可被 Pause/Resume、做 Checkpoint、被 SandboxUpdateOps 升级,最终在使用完毕或超时后回收。
1.4 整体架构
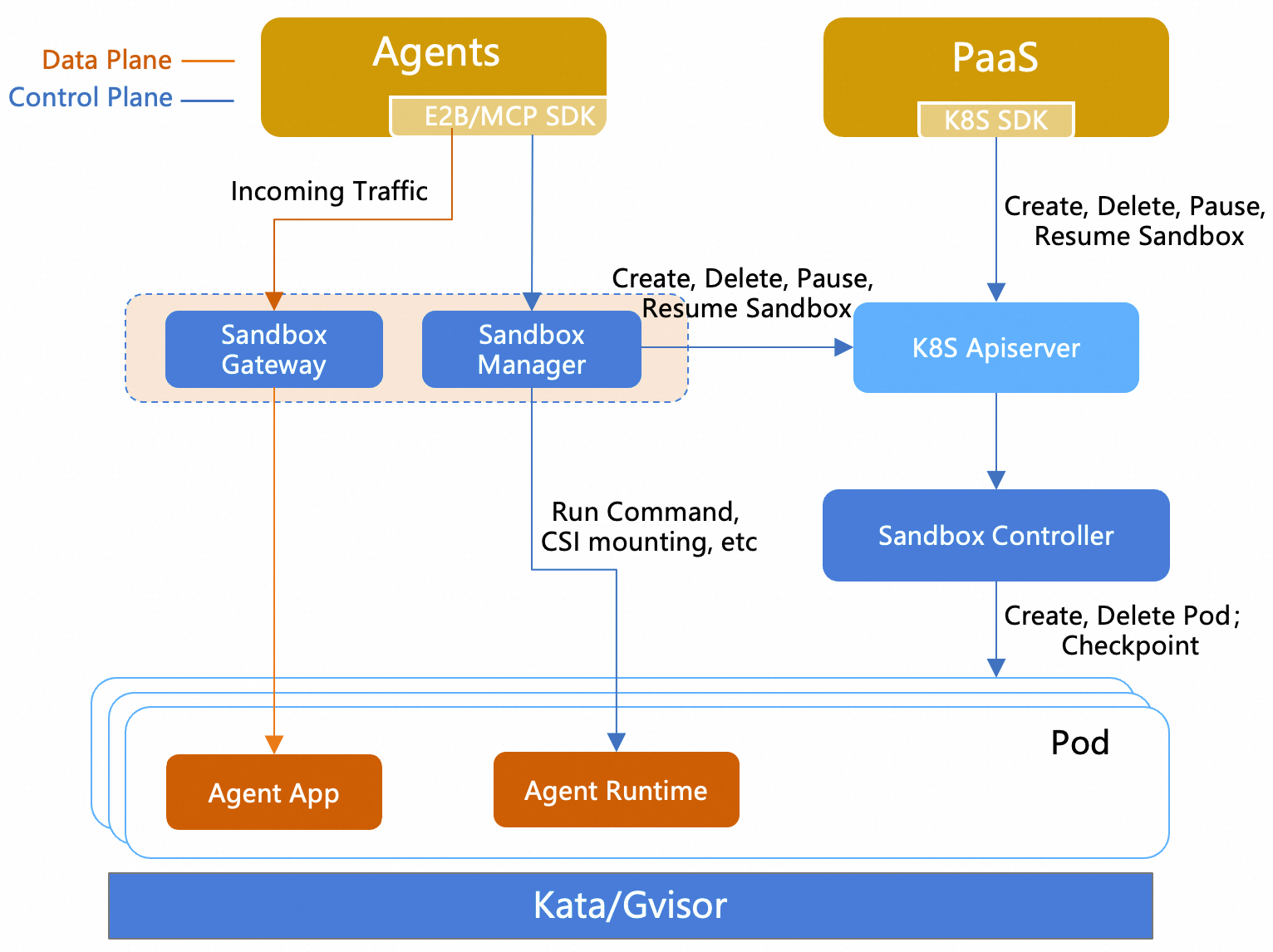
OpenKruise Agents 在控制面和数据面做了清晰拆分,由四个组件构成:
- sandbox-manager:无状态后端服务,对外提供 E2B API 和 MCP API,是 SDK / 外部 Agent 框架的接入入口;
- sandbox-gateway:基于 Envoy filter 实现的轻量网关,按 namespace + sandbox name + port 精准路由入站流量到具体 Pod,最小化对 K8s Service 的依赖;
- sandbox-controller:一组 controller,负责 SandboxSet / SandboxClaim / SandboxUpdateOps 等 CRD 的 reconcile,同时承载相关 admission webhook;
- agent-runtime:作为 Sidecar 注入到 Sandbox Pod 内,提供 E2B envd 兼容的命令与文件操作、动态 CSI 挂载、Lifecycle Hook 脚本执行等运行时能力。
这一分层让 OpenKruise Agents 既能"对上"无缝兼容 E2B 生态,又能"对下"完整复用 K8s 原生工作负载能力(滚动更新、Pod 拓扑感知、PVC、CSI 等)。
1.5 与 E2B 的关系
E2B 是当前 AI Agent 领域使用最广泛的开源 Sandbox SDK,提供 Python / JavaScript 客户端。OpenKruise Agents 的 sandbox-manager 同时兼容原生 E2B 协议和扩展协议:
from e2b_code_interpreter import Sandbox
# 标准 E2B 用法——零改动直接运行在 OpenKruise Agents 集群上
with Sandbox.create(template="demo") as sbx:
print(sbx.get_info())
# 通过扩展 metadata 使用 OpenKruise Agents 增强能力
sbx = Sandbox.create(template="demo", metadata={
# 原地镜像替换:认领时将预热池中的默认镜像替换为指定版本
"e2b.agents.kruise.io/image": "my-registry/sandbox:v2",
# 原地 CPU 变配(VPA):按需调整资源,无需重建 Pod
"e2b.agents.kruise.io/cpu-request": "2000m",
"e2b.agents.kruise.io/cpu-limit": "4",
# 动态存储挂载:认领时自动挂载持久化卷
"e2b.agents.kruise.io/csi-volume-config": '[{"pvName":"nas-pv-sandbox-system","mountPath":"/data-nas","subPath":"data-subPath"},{...}]',
})
其中 template="demo" 对应一个名为 demo 的 SandboxSet。标准 E2B 代码无需任何修改即可运行;而通过 e2b.agents.kruise.io/* 扩展 metadata,可在认领阶段一次性完成镜像替换、资源变配、存储挂载等操作,无需额外 API 调用。
换言之,OpenKruise Agents 接住了 E2B 的应用语义,同时将底层转化为可被 K8s 平台团队治理的工作负载。 有 E2B 存量代码的团队几乎是 drop-in 替换;平台团队则获得了滚动升级、Quota、Sidecar 注入、PV 动态挂载等完整的云原生工具链。
二、v0.3.0 重点特性:升级运维、成本优化、多租户治理
如果说此前版本解决的是"Sandbox 怎么快速交付",那么 v0.3.0 的核心命题是"交付之后,怎么管好、用好、升级好"——批量升级让 Sandbox 版本可控可收敛,VPA 让资源按需分配不浪费,多租户让共享集群权责分明。
2.1 问题背景:为什么 Claimed Sandbox 升级这么难
一个集群里通常同时存在两类 Sandbox:
- 未分配 Sandbox:驻留在 SandboxSet 预热池中、尚未被认领的 idle 实例;
- 已分配 Sandbox(Claimed Sandbox):已被 Agent 领走、正承载用户会话或长任务的活跃实例。
前者的升级轻而易举——修改 SandboxSet 的 spec.template,控制器按 maxUnavailable 滚动替换即可。真正的难点在后者:
- 这些 Sandbox 上跑着用户状态(工作空间文件、模型缓存、长会话上下文),不能粗暴
kubectl delete pod; - 它们由 Sandbox CRD 直接管理,不隶属任何 ReplicaSet/Deployment,原生 K8s 缺少"批量升级一组独立 Sandbox"的机制;
- 升级不可避免涉及 Pod 重建(更换镜像、改 resources、加 Volume 等),IP 和内存状态都会丢失,业务层需要明确的 hook 点完成"备份 → 重建 → 恢复"。
v0.3.0 围绕升级运维交付了两项相互配套的特性:SandboxUpdateOps 批量升级 CR 与 Recreate 策略 + Lifecycle Hook。
2.2 SandboxUpdateOps:面向 Claimed Sandbox 的批量升级 CR
SandboxUpdateOps(短名 suo)是 v0.3.0 新增的 CRD,定位清晰:为一批已认领、正在运行的 Sandbox 一次性下发升级任务。
设计模型
可类比 Kubernetes Job——一次性、有明确目标集合、有终态。由三块核心配置组成:
selector:通过 Label 选择目标 Sandbox 集合(支持matchLabels/matchExpressions),通常按agents.kruise.io/sandbox-template=<sandboxset-name>标签批量选中某类 Sandbox;updateStrategy.maxUnavailable:升级过程中同时处于升级中的 Sandbox 上限,支持绝对值或百分比,默认为 1——这是灰度升级的核心旋钮;patch:以 Strategic Merge Patch 方式应用到每个 Sandbox 的spec.template,承载变更内容——可更换镜像、增删 Volume、调整环境变量等。
最小可用示例:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxUpdateOps
metadata:
name: upgrade-my-sandboxes
namespace: default
spec:
selector:
matchLabels:
agents.kruise.io/sandbox-template: my-sandbox-pool
updateStrategy:
maxUnavailable: 2
patch:
spec:
containers:
- name: sandbox
image: my-registry/sandbox-image:v2
关键约束
- 同 Namespace 同时只允许一个
Updating状态的 SandboxUpdateOps——避免多任务相互干扰,需等前一个完成或删除后再发起; - 仅升级
Phase为Running或Upgrading的 Sandbox,不支持休眠 / 唤醒中的实例; - SandboxUpdateOps 是一次性任务,执行失败需删除后重新创建(与 Job 语义一致);
- 仅适用于 Claimed Sandbox,预热池中未分配的 Sandbox 走 SandboxSet 的
updateStrategy。
观测与状态
升级进度可通过 kubectl get suo 直观查看:
NAME PHASE TOTAL UPDATED UPDATING FAILED AGE
upgrade-my-sandboxes Updating 1000 66 100 0 2m32s
PHASE:Pending/Updating/Completed/FailedTOTAL:selector 选中的 Sandbox 总数UPDATED:已成功升级的数量UPDATING:正在升级中的数量(受maxUnavailable约束)FAILED:升级失败的数量
每个被升级的 Sandbox 会标记 agents.kruise.io/update-ops=<suo-name> 标签,便于按 UpdateOps 维度过滤:
kubectl get sandbox -l agents.kruise.io/update-ops=upgrade-my-sandboxes
2.3 Recreate 升级策略 + Lifecycle Hook:让"会重建 Pod"的升级也能保留数据
SandboxUpdateOps 是"任务编排层",Recreate 策略 + Lifecycle Hook 是单个 Sandbox 升级的"执行层"。两者配合,构成 v0.3.0 升级链路的核心。
升级流程
如下图所示,Recreate 策略将单个 Sandbox 的升级拆为严格串行的三阶段:PreUpgrade(执行备份脚本,将数据写入 OSS / NAS) → UpgradePod(删除旧 Pod,按新模板重建) → PostUpgrade(从外部存储恢复数据)。任一阶段失败即停止,并进入对应的 Failed 状态。
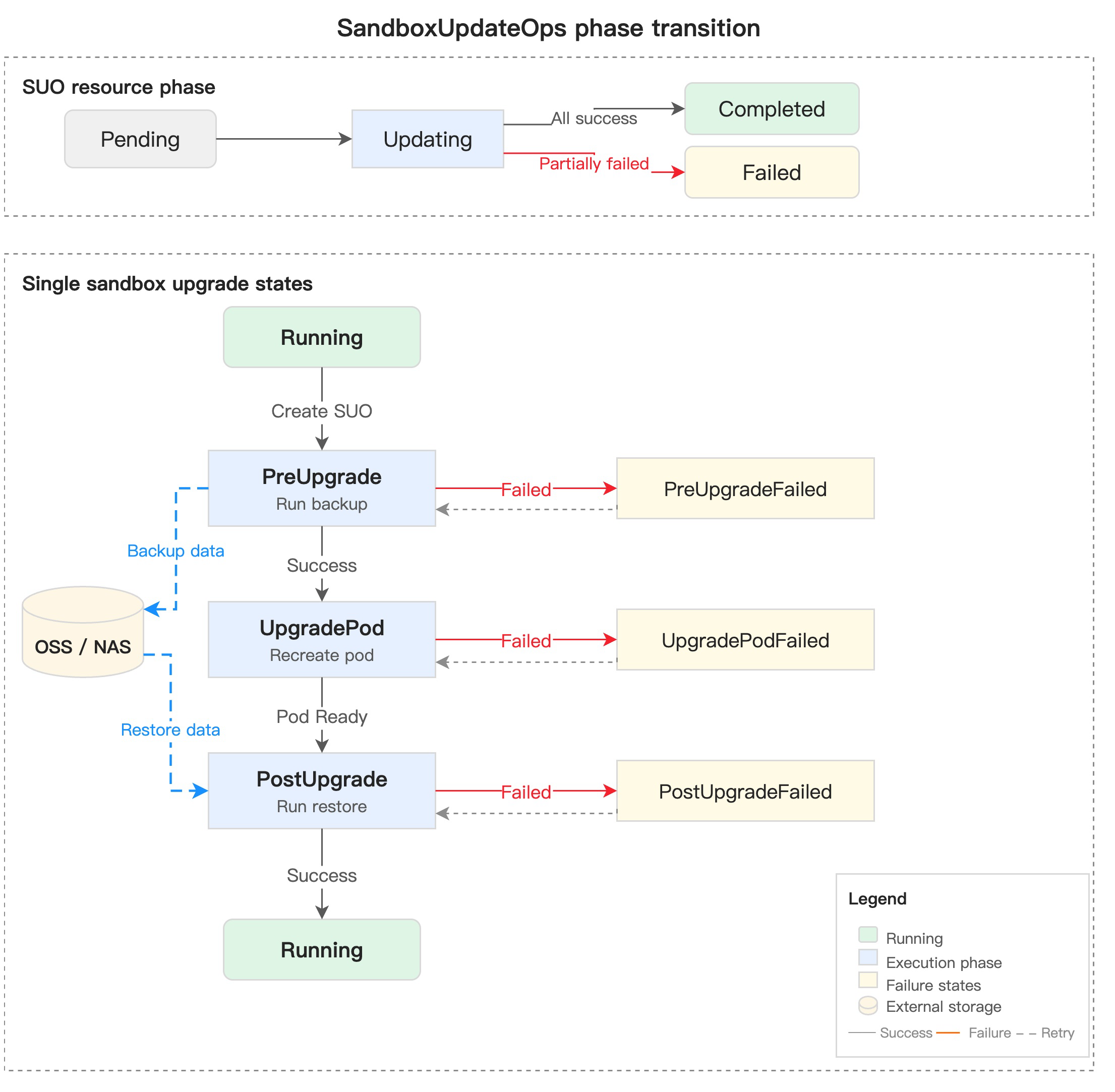
之所以叫 Recreate,是因为升级路径必须重建底层 Pod(换镜像、改资源、改挂载都无法纯 in-place 完成)。Pod 重建意味着 IP 变更、内存状态清零、rootfs 可写层丢失——因此 OpenKruise Agents 在重建前后各开一个 Hook,由用户自行完成数据的备份与恢复。
preUpgrade / postUpgrade Hook
preUpgrade:在旧 Pod 被销毁之前执行。典型用途:将工作目录、长会话上下文、模型缓存等打包备份到 OSS / NAS 等持久化存储;postUpgrade:在新 Pod Ready 之后执行。典型用途:从持久化存储还原备份数据到工作目录。
Hook 的执行依赖两个 Sidecar:
- agent-runtime:提供 E2B envd 兼容的命令执行能力,所有 Hook 脚本最终通过它在 Sandbox 内部运行;
- csi:动态挂载能力,若备份/恢复需要写入 OSS / NAS 则必须注入。
以下是一个完整示例——将 OpenClaw 工作空间 .openclaw 在升级前打包到动态挂载的 OSS 目录 /backup,升级后恢复:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxUpdateOps
metadata:
name: upgrade-with-backup
namespace: default
spec:
selector:
matchLabels:
agents.kruise.io/sandbox-template: openclaw-sbs
updateStrategy:
maxUnavailable: 10%
patch:
spec:
containers:
- name: gateway
image: ghcr.io/openclaw/openclaw:2026.4.11 # 新版本镜像
lifecycle:
preUpgrade:
exec:
command:
- /bin/bash
- -c
- |
set -e
cd /root/
tar -czf openclaw-state-v1.tgz .openclaw
mv openclaw-state-v1.tgz /backup
echo 'preUpgrade success'
timeoutSeconds: 600
postUpgrade:
exec:
command:
- /bin/bash
- -c
- |
set -e
rm -rf /root/.openclaw
cp /backup/openclaw-state-v1.tgz /root/openclaw-state-v1.tgz
tar -xzvf /root/openclaw-state-v1.tgz -C /root
rm -rf /root/openclaw-state-v1.tgz
timeoutSeconds: 600
细粒度状态机:精确定位每个 Sandbox 的失败点
Sandbox 在升级过程中处于 Phase=Upgrading,通过 status.conditions[type=Upgrading].reason 暴露当前阶段:
| Reason | 含义 |
|---|---|
PreUpgrade | 正在执行 preUpgrade 脚本 |
PreUpgradeFailed | preUpgrade 脚本执行失败 |
UpgradePod | 正在根据新模板重建 Pod |
UpgradePodFailed | 新 Pod 启动失败(镜像拉取、启动超时、Crash 等) |
PostUpgrade | 正在执行 postUpgrade 脚本 |
PostUpgradeFailed | postUpgrade 脚本执行失败 |
Succeeded | 升级完成 |
这种设计让排障非常直观——kubectl get sandbox <name> -o yaml 查看 conditions 即可定位卡在哪一步及具体错误信息。失败后的处理策略:
- PreUpgrade 失败:底层容器未动,数据安全。修脚本或回滚 patch 即可;
- UpgradePod 失败:旧 Pod 已销毁,新 Pod 未起来。推荐用 Checkpoint 恢复,或把 patch 回滚到旧镜像。注意此时 preUpgrade 已执行过,重试时须去掉 preUpgrade 避免重复备份;
- PostUpgrade 失败:新 Pod 已就绪但恢复脚本出错。修脚本后新建一个只带
postUpgrade的 SandboxUpdateOps 重试。
暂停进行中的升级
若升级途中发现问题需要"刹车",可直接设置 paused: true:
spec:
paused: true
这只会阻止新的 Sandbox 进入升级队列,已在升级中的 Sandbox 仍会按既有流程完成。
2.4 In-Place CPU Resize:小规格预热,Claim 时按需扩配降成本
解决什么问题
预热池的核心价值在于"启动快"——预先拉起 Sandbox,请求到达时直接认领,省掉 Pod 启动耗时。从成本角度,预热池应统一使用最小规格(如 0.5C1G)以降低空闲资源占用。但现实中不同 Agent 任务的资源需求差异巨大——数据分析可能需要 4C,大模型本地推理可能要 8C。
此前的应对方案各有缺陷:为每个规格各维护一个 SandboxSet(池子分散、管理复杂);统一按最大规格预热(空闲时资源浪费严重);认领后重建 Pod 调整规格(彻底丧失预热优势)。
v0.3.0 利用 Kubernetes 原生 In-Place Pod Vertical Scaling,在 Claim 阶段对热池 Sandbox 执行"原地变配"——Pod 不重建、IP 不变、容器不重启,仅调整 CPU requests/limits。既保留了预热池的亚秒级交付,又满足了按需差异化配置的诉求。
用法:E2B 与 SandboxClaim 双协议
通过 E2B SDK(使用扩展 metadata):
from e2b_code_interpreter import Sandbox
sbx = Sandbox.create(template="demo", metadata={
"e2b.agents.kruise.io/cpu-request": "1000m",
"e2b.agents.kruise.io/cpu-limit": "2"
})
通过 SandboxClaim CR 声明式使用:
apiVersion: agents.kruise.io/v1alpha1
kind: SandboxClaim
metadata:
name: demo-sandbox-claim
namespace: default
spec:
templateName: demo
inplaceUpdate:
resources:
requests:
cpu: "1000m"
limits:
cpu: "2"
使用约束
- 当前仅支持 CPU resize,memory 等其他资源会被忽略;
- 仅对主容器生效(Sidecar 不变);
- 变配后不允许改变 Pod 的 QoS class(如从 Guaranteed 降为 Burstable 会被拒绝);
- 依赖 Kubernetes in-place pod resize——推荐 K8s 1.33+(该 feature 已 beta 且默认开启);K8s 1.27–1.32 需手动开启
InPlacePodVerticalScalingfeature gate; - 该能力受
SandboxInPlaceResourceResizefeature gate 控制,OpenKruise Agents 侧默认开启; - 可与 Claim 时的 image 替换(
inplaceUpdate.image)组合使用,一次认领同时换镜像、调资源。
2.5 Team-based 多租户隔离与 API Key 授权体系
v0.3.0 引入了完整的多租户授权模型,为生产环境下多团队共享集群提供了清晰的隔离边界。
核心设计:Team Name = Kubernetes Namespace。 每个 Team 的身份由 Team Name 唯一标识,并直接映射到一个已存在的 Kubernetes Namespace。这意味着 Namespace 本身的隔离性天然成为 Sandbox 的授权边界——无需引入额外的隔离抽象,租户只能操作自身 Namespace 内的资源。
两级角色模型:
| 角色 | 能力范围 |
|---|---|
管理员(admin Team) | 集群级权限:为任意 Team 颁发/吊销 API Key、查看全部 Team 和 Sandbox |
| 普通租户 | Namespace 级权限:管理本 Team 的 Key、只能访问由自身 Key 创建的 Sandbox |
内置的 admin API Key 随 sandbox-manager 启动初始化,出于集群可控性考虑不可被删除。
API Key 即身份凭证。 客户端调用 sandbox-manager 任何接口时,通过 X-API-KEY 请求头携带凭证。API Key 决定了三件事:调用方属于哪个 Team、是否为管理员、以及可访问哪些 Sandbox。sandbox-manager 提供了一组兼容 E2B 协议的 HTTP 接口(GET/POST/DELETE /api-keys、GET /teams)用于 Key 的全生命周期管理。
可插拔的 Key 存储后端。 API Key 的持久化支持两种后端,通过 --e2b-key-storage 参数切换:
secret(默认):零依赖方案,将所有 Key 存入一个 Kubernetes Secret,适合试用或单租户场景(建议 Key 总数 ≤ 500);mysql:通过 GORM 持久化到 MySQL,仅存储 HMAC-SHA256 哈希,绝不落盘明文。适合多租户、多副本共享 Key 存储的生产部署,无容量瓶颈。
典型的多租户工作流如下:集群管理员持 admin Key 为各 Team 颁发首个 API Key → 租户使用自身 Key 自助创建更多 Key(如 CI Runner 专用 Key) → 租户通过 Key 创建和管理属于自身 Namespace 的 Sandbox → 管理员可全局观测和治理所有 Team 的资源用量。
三、未来规划与社区共建
v0.3.0 补齐了"升级运维"这块拼图后,社区的下一阶段重点将集中在:
- 流量管理与安全策略(#433):引入
TrafficPolicy/GlobalTrafficPolicy(L3/L4)和SecurityProfile(L7)两组 CRD,为 Sandbox 提供细粒度的出站流量管控——支持 IP/端口级别的 allow-deny 规则,以及基于 HTTP host/path/method 的 L7 策略(拦截、限流、身份注入、流量镜像等); - 安全身份集成(Proposal):引入可插拔的 Gateway Identity Provider 框架,在 Sandbox 通过网关访问外部服务时,由外部身份服务颁发绑定到 Sandbox/Agent 的访问令牌,并在网关层自动完成凭证替换——支持令牌自动刷新、mTLS 认证、优雅降级(身份服务不可用时回退到 UUID token 不阻塞交付);
如果你正在做 AI Agent 平台、Code Interpreter 服务、长会话 Codespace、强化学习训练框架,或者想为团队的 E2B 部署找一个云原生底座,欢迎给 openkruise/agents 点个 Star,也欢迎通过以下方式加入社区:
- GitHub:https://github.com/openkruise/agents
- Slack:Kubernetes Slack #openkruise 频道
- 钉钉群:搜索群号
23330762 - 微信:添加
openkruise让机器人拉群 - 双周社区例会(中文):每周四 19:30 GMT+8
OpenKruise Agents v0.3.0 已在 GitHub Release 与各大镜像仓库就绪,欢迎升级体验。期待你的反馈和 Pull Request。