CloneSet
CloneSet 控制器提供了高效管理无状态应用的能力,它可以对标原生的 Deployment,但 CloneSet 提供了很多增强功能。
按照 Kruise 的命名规范,CloneSet 是一个直接管理 Pod 的 Set 类型 workload。 一个简单的 CloneSet yaml 文件如下:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
labels:
app: sample
name: sample
spec:
replicas: 5
selector:
matchLabels:
app: sample
template:
metadata:
labels:
app: sample
spec:
containers:
- name: nginx
image: nginx:alpine
扩缩容功能
支持 PVC 模板
CloneSet 允许用户配置 PVC 模板 volumeClaimTemplates,用来给每个 Pod 生成独享的 PVC,这是 Deployment 所不支持的。
如果用户没有指定这个模板,CloneSet 会创建不带 PVC 的 Pod。
一些注意点:
- 每个被自动创建的 PVC 会有一个 ownerReference 指向 CloneSet,因此 CloneSet 被删除时,它创建的所有 Pod 和 PVC 都会被删除。
- 每个被 CloneSet 创建的 Pod 和 PVC,都会带一个
apps.kruise.io/cloneset-instance-id: xxx的 label。关联的 Pod 和 PVC 会有相同的 instance-id,且它们的名字后缀都是这个 instance-id。 - 如果一个 Pod 被 CloneSet controller 缩容删除时,这个 Pod 关联的 PVC 都会被一起删掉。
- 如果一个 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVC 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的 instance-id 并关联原来的 PVC。
- 当 Pod 被重建升级时,关联的 PVC 会跟随 Pod 一起被删除、新建。
- 当 Pod 被原地升级时,关联的 PVC 会持续使用。
以下是一个带有 PVC 模板的例子:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
labels:
app: sample
name: sample-data
spec:
replicas: 5
selector:
matchLabels:
app: sample
template:
metadata:
labels:
app: sample
spec:
containers:
- name: nginx
image: nginx:alpine
volumeMounts:
- name: data-vol
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data-vol
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
FEATURE STATE: Kruise v1.4.0
如果一个 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVCs 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的 instance-id 并关联原来的 PVCs。
然而,如果 Pod 所在的 Node 出现异常,复用可能会导致新 Pod 启动失败,详情参考 issue 1099。为了解决这个问题,您可以设置字段 DisablePVCReuse=true。在这种情况下,与 Pod 相关的 PVCs 将被自动删除,不再被复用。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
...
replicas: 4
scaleStrategy:
disablePVCReuse: true
当 volumeClaimTemplates 改变时,将会重建升级 Pod 和关联的 volume
FEATURE STATE: Kruise v1.7.0
默认情况下,如果 image 和 volumeClaimTemplates 同时改变,CloneSet 将会原地升级 Pod,并且不会重建 volume,导致 volumeClaimTemplates 配置不生效。
- 初始情况下,image=nginx:v1, volumeClaimTemplates=20G
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
template:
spec:
containers:
- name: nginx
image: nginx:v1
volumeMounts:
- name: data-vol
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data-vol
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
- 将 image变更为nginx:v2,volumeClaimTemplates=40G
- CloneSet 会原地升级Pod,并不会重建 volume,因此新 Pod 对应的 volume 大小还是 20G,并没有生效最新的。
针对上述场景,你可以打开 feature-gate RecreatePodWhenChangeVCTInCloneSetGate=true。CloneSet 将会重建 Pod 和 volumes 升级, 此时,新 Pod 的 volume 将为 40G。
注意:如果你只变更 volumeClaimTemplates 字段,依旧不会触发 Pod 升级,需要同步着修改 Labels、Annotations、Image、Env 等字段才可以。
指定 Pod 缩容
当一个 CloneSet 被缩容时,有时候用户需要指定一些 Pod 来删除。这对于 StatefulSet 或者 Deployment 来说是无法实现的,因为 StatefulSet 要根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除。
CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字。参考下面这个例子:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
replicas: 4
scaleStrategy:
podsToDelete:
- sample-9m4hp
当控制器收到上面这个 CloneSet 更新之后,会确保 replicas 数量为 4。如果 podsToDelete 列表里写了一些 Pod 名字,控制器会优先删除这些 Pod。
对于已经被删除的 Pod,控制器会自动从 podsToDelete 列表中清理掉。
如果你只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod。
另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签。
相比于手动直接删除 Pod,使用 podsToDelete 或 apps.kruise.io/specified-delete: true 方式会有 CloneSet 的 maxUnavailable/maxSurge 来保护删除,
并且会触发 PreparingDelete 生命周期 hook (见下文)。
缩容顺序
- 未调度 < 已调度
- PodPending < PodUnknown < PodRunning
- Not ready < ready
- 较小 pod-deletion cost < 较大 pod-deletion cost
- 较大打散权重 < 较小
- 处于 Ready 时间较短 < 较长
- 容器重启次数较多 < 较少
- 创建时间较短 < 较长
Pod deletion cost
FEATURE STATE: Kruise v0.9.0
controller.kubernetes.io/pod-deletion-cost 是从 Kubernetes 1.21 版本后加入的 annotation,Deployment/ReplicaSet 在缩容时会参考这个 cost 数值来排序。 CloneSet 从 Kruise v0.9.0 版本后也同样支持了这个功能。
用户可以把这个 annotation 配置到 pod 上,值的范围在 [-2147483647, 2147483647]。 它表示这个 pod 相较于同个 CloneSet 下其他 pod 的 "删除代价",代价越小的 pod 删除优先级相对越高。 没有设置这个 annotation 的 pod 默认 deletion cost 是 0。
Deletion by Spread Constraints
FEATURE STATE: Kruise v0.10.0
原始 proposal(设计文档)在这里。
目前,CloneSet 支持 按同节点打散 和 按 pod topology spread constraints 打散。
如果在 CloneSet template 中存在 Pod Topology Spread Constraints 规则定义,则 controller 在这个 CloneSet 缩容的时候会根据 spread constraints 规则来所打散并选择要删除的 pod。 否则,controller 默认情况下是按同节点打散来选择要缩容的 pod。
短 hash
FEATURE STATE: Kruise v0.9.0
默认情况下,CloneSet 在 Pod label 中设置的 controller-revision-hash 值为 ControllerRevision 的完整名字,比如
apiVersion: v1
kind: Pod
metadata:
labels:
controller-revision-hash: demo-cloneset-956df7994
它是通过 CloneSet 名字和 ControllerRevision hash 值拼接而成。 通常 hash 值长度为 8~10 个字符,而 Kubernetes 中的 label 值不能超过 63 个字符。 因此 CloneSet 的名字一般是不能超过 52 个字符的。
因此 CloneSetShortHash 这个新的 feature-gate 被引入。
如果它被打开,CloneSet 会将 controller-revision-hash 的值只设置为 hash 值,比如 956df7994,因此 CloneSet 名字则不会有任何限制了。
不用担心,即使打开了 CloneSetShortHash,CloneSet 仍然会识别和管理过去存量的 revision label 为完整格式的 Pod。
从 Kruise v1.1.0 版本开始,CloneSet 还会给 Pod 中加入另一个 pod-template-hash 标签,它永远是短 hash 的形式。
流式扩容
FEATURE STATE: Kruise v1.0.0
CloneSet 扩容时可以指定 ScaleStrategy.MaxUnavailable 来限制扩容的步长,以达到服务应用影响最小化的目的。
它可以设置为一个绝对值或者百分比,如果不填,则 Kruise 会设置为默认值为 nil,即表示不设限制。
该字段可以配合 Spec.MinReadySeconds 字段使用, 例如:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
上述配置能达到的效果是:在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过一分钟后,CloneSet 才会执行创建下一个 Pod 的操作。
升级功能
升级类型
CloneSet 提供了 4 种升级方式,默认为 ReCreate:
ReCreate: 控制器会删除旧 Pod 和它的 PVC,然后用新版本重新创建出来。InPlaceIfPossible: 控制器会优先尝试原地升级 Pod,如果不行再采用重建升级。当前, 仅支持容器镜像等字段的原地升级。InPlaceOnly: 控制器只允许采用原地升级。因此,用户只能修改容器镜像等字段,如果尝试修改其他字段会被 Kruise 拒绝。OnDelete: FEATURE STATE: Kruise v1.9.0。控制器不会自动升级 Pod。只有在 Pod 被手动删除时才会进行更新。版本跟踪和有序滚动重启将被禁用。适用于需要手动控制每个 Pod 更新场景。
请阅读原地升级概念了解更多原地升级的细节。
我们还在原地升级中提供了 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。
这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
type: InPlaceIfPossible
inPlaceUpdateStrategy:
gracePeriodSeconds: 10
Template 和 revision
spec.template 中定义了当前 CloneSet 中最新的 Pod 模板。
控制器会为每次更新过的 spec.template 计算一个 revision hash 值,比如针对开头的 CloneSet 例子,
控制器会为 template 计算出 revision hash 为 sample-744d4796cc 并上报到 CloneSet status 中。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
generation: 1
# ...
spec:
replicas: 5
# ...
status:
observedGeneration: 1
readyReplicas: 5
replicas: 5
currentRevision: sample-d4d4fb5bd
updateRevision: sample-d4d4fb5bd
updatedReadyReplicas: 5
updatedReplicas: 5
# ...
这里是对 CloneSet status 中的字段说明:
status.replicas: Pod 总数status.readyReplicas: ready Pod 数量status.availableReplicas: ready and available Pod 数量 (满足minReadySeconds, 且 lifecycle state 为Normal)status.currentRevision: 最近一次全量 Pod 推平版本的 revision hash 值status.updateRevision: 最新版本的 revision hash 值status.updatedReplicas: 最新版本的 Pod 数量status.updatedReadyReplicas: 最新版本的 ready Pod 数量 FEATURE STATE: Kruise v1.2.0status.expectedUpdatedReplicas: 需要升级到最新版本 Pod 的数量(包含已经升级的数量),该字段根据用户当前设置的.spec.updateStrategy.partition字段计算得到。
Partition 分批灰度
Partition 的语义是 保留旧版本 Pod 的数量或百分比,默认为 0。这里的 partition 不表示任何 order 序号。
如果在发布过程中设置了 partition:
- 如果是数字,控制器会将
(replicas - partition)数量的 Pod 更新到最新版本。 - 如果是百分比,控制器会将
(replicas * (100% - partition))数量的 Pod 更新到最新版本。
FEATURE STATE: Kruise v1.2.0
- 如果
partition是百分比, 并且满足partition < 100% && replicas > 1, CloneSet 会保证 至少有一个 Pod 会被升级到最新版本。 - 用户可以使用
.status.updatedReplicas >= .status.ExpectedUpdatedReplicas条件,来判断在当前partition字段的限制下,CloneSet 是否已经完成了预期数量 Pod 的版本升级。
比如,我们将 CloneSet 例子的 image 更新为 nginx:mainline 并且设置 partition=3。过了一会,查到的 CloneSet 如下:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
# ...
generation: 2
spec:
replicas: 5
template:
metadata:
labels:
app: sample
spec:
containers:
- image: nginx:mainline
imagePullPolicy: Always
name: nginx
updateStrategy:
partition: 3
# ...
status:
observedGeneration: 2
readyReplicas: 5
replicas: 5
currentRevision: sample-d4d4fb5bd
updateRevision: sample-56dfb978d4
updatedReadyReplicas: 2
updatedReplicas: 2
注意 status.updateRevision 已经更新为 sample-56dfb978d4 新的值。
由于我们设置了 partition=3,控制器只升级了 2 个 Pod。
$ kubectl get pod -L controller-revision-hash
NAME READY STATUS RESTARTS AGE CONTROLLER-REVISION-HASH
sample-chvnr 1/1 Running 0 6m46s sample-d4d4fb5bd
sample-j6c4s 1/1 Running 0 6m46s sample-d4d4fb5bd
sample-ns85c 1/1 Running 0 6m46s sample-d4d4fb5bd
sample-jnjdp 1/1 Running 0 10s sample-56dfb978d4
sample-qqglp 1/1 Running 0 18s sample-56dfb978d4
通过 partition 回滚
FEATURE STATE: Kruise v0.9.0
默认情况下,partition 只控制 Pod 更新到 status.updateRevision 新版本。
也就是说以上面这个 CloneSet 来看,当 partition 5 -> 3 时,CloneSet 会升级 2 个 Pod 到 status.updateRevision 版本。
而当把 partition 3 -> 5 修改回去时,CloneSet 不会做任何事情。
但是如果你启用了 CloneSetPartitionRollback 这个 feature-gate,
上面这个场景下 CloneSet 会把 2 个 status.updateRevision 版本的 Pod 重新回滚为 status.currentRevision 版本。
MaxUnavailable 最大不可用数量
MaxUnavailable 是 CloneSet 限制下属最多不可用的 Pod 数量。
它可以设置为一个绝对值或者百分比,如果不填 Kruise 会设置为默认值 20%。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
maxUnavailable: 20%
从 Kruise v0.9.0 版本开始,maxUnavailable 不仅会保护发布,也会对 Pod 指定删除生效。
也就是说用户通过 podsToDelete 或 apps.kruise.io/specified-delete: true 来指定一个 Pod 期望删除,
CloneSet 只会在当前不可用 Pod 数量(相对于 replicas 总数)小于 maxUnavailable 的时候才执行删除。
MaxSurge 最大弹性数量
MaxSurge 是 CloneSet 控制最多能扩出来超过 replicas 的 Pod 数量。
它可以设置为一个绝对值或者百分比,如果不填 Kruise 会设置为默认值 0。
如果发布的时候设置了 maxSurge,控制器会先多扩出来 maxSurge 数量的 Pod(此时 Pod 总数为 (replicas+maxSurge)),然后再开始发布存量的 Pod。
然后,当新版本 Pod 数量已经满足 partition 要求之后,控制器会再把多余的 maxSurge 数量的 Pod 删除掉,保证最终的 Pod 数量符合 replicas。
要说明的是,maxSurge 不允许配合 InPlaceOnly 更新模式使用。
另外,如果是与 InPlaceIfPossible 策略配合使用,控制器会先扩出来 maxSurge 数量的 Pod,再对存量 Pod 做原地升级。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
maxSurge: 3
从 Kruise v0.9.0 版本开始,maxSurge 不仅会保护发布,也会对 Pod 指定删除生效。
也就是说用户通过 podsToDelete 或 apps.kruise.io/specified-delete: true 来指定一个 Pod 期望删除,
CloneSet 有可能会先创建一个新 Pod、等待它 ready 之后、再删除旧 Pod。这取决于当时的 maxUnavailable 和实际不可用 Pod 数量。
比如:
- 对于一个 CloneSet
maxUnavailable=2, maxSurge=1且有一个pod-a处于不可用状态, 如果你对另一个pod-b打标apps.kruise.io/specified-delete: true或将它的名字加入podsToDelete, 那么 CloneSet 会立即删除它,然后创建一个新 Pod。 - 对于一个 CloneSet
maxUnavailable=1, maxSurge=1且有一个pod-a处于不可用状态, 如果你对另一个pod-b打标apps.kruise.io/specified-delete: true或将它的名字加入podsToDelete, 那么 CloneSet 会先新建一个 Pod、等待它 ready,最后再删除pod-b。 - 对于一个 CloneSet
maxUnavailable=1, maxSurge=1且有一个pod-a处于不可用状态, 如果你对这个pod-a打标apps.kruise.io/specified-delete: true或将它的名字加入podsToDelete, 那么 CloneSet 会立即删除它,然后创建一个新 Pod。 - ...
升级顺序
当控制器选择 Pod 做升级时,默认是有一套根据 Pod phase/conditions 的排序逻辑:
unscheduled < scheduled, pending < unknown < running, not-ready < ready。
在此之外,CloneSet 也提供了增强的 priority(优先级) 和 scatter(打散) 策略来允许用户自定义发布顺序。
优先级策略
这个策略定义了控制器计算 Pod 发布优先级的规则,所有需要更新的 Pod 都会通过这个优先级规则计算后排序。
目前 priority 可以通过 weight(权重) 和 order(序号) 两种方式来指定。
weight: Pod 优先级是由所有 weights 列表中的 term 来计算 match selector 得出。如下:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
priorityStrategy:
weightPriority:
- weight: 50
matchSelector:
matchLabels:
test-key: foo
- weight: 30
matchSelector:
matchLabels:
test-key: bar
order: Pod 优先级是由 orderKey 的 value 决定,这里要求对应的 value 的结尾能解析为 int 值。比如 value "5" 的优先级是 5,value "sts-10" 的优先级是 10。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
priorityStrategy:
orderPriority:
- orderedKey: some-label-key
打散策略
这个策略定义了如何将一类 Pod 打散到整个发布过程中。
比如,针对一个 replica=10 的 CloneSet,我们在 3 个 Pod 中添加了 foo=bar 标签、并设置对应的 scatter 策略,那么在发布的时候这 3 个 Pod 会排在第 1、6、10 个发布。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
scatterStrategy:
- key: foo
value: bar
注意:
- 尽管
priority和scatter策略可以一起设置,但我们强烈推荐同时只用其中一个。 - 如果使用了
scatter策略,我们强烈建议只配置一个 term (key-value)。否则,实际的打散发布顺序可能会不太好理解。
最后要说明的是,使用上述发布顺序策略都要求对特定一些 Pod 打标,这是在 CloneSet 中没有提供的。
发布暂停
用户可以通过设置 paused 为 true 暂停发布,不过控制器还是会做 replicas 数量管理:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
paused: true
进度期限机制
FEATURE STATE: Kruise v1.9.0
.spec.progressDeadlineSeconds 是一个可选配置项,用于定义 CloneSet 控制器在判定升级部署失败前的最大等待时间(秒)。当超过此期限仍未取得进展时,CloneSet 控制器将在资源状态中记录相应的状况条目:
type: Progressing
status: False
reason: ProgressDeadlineExceeded
CloneSet 默认不会设置该值,因此在默认情况下 CloneSet 控制器不会在 .status.conditions 上记录相应的状况条目。
一旦设置该值,CloneSet 控制器会在设定的时间内持续检查部署操作。上层编排系统可利用此状态来触发对应的动作,例如进行 CloneSet 的回滚操作(即使此状态判定为超时,也不会影响底层 CloneSet 控制器继续对 Pod 进行滚动升级)。
注意:
如果指定,则此字段值需要大于
.spec.minReadySeconds取值。
因此,通过配置 .spec.progressDeadlineSeconds,会使得 CloneSet 在其生命周期中会经历多种状态:
- Progressing(进行中):部署过程正在进行。
- Available(可用):分组部署完成或者整体部署成功。
- Failed(失败):部署超时以至于无法继续进行。
Progressing 状态原因说明
以下为 Progressing 状况条目为 True 的情况:
| Reason | Message | Description |
|---|---|---|
| CloneSetUpdated | CloneSet is progressing/CloneSet is resumed | 发布升级过程中 |
| CloneSetAvailable | CloneSet is available | 发布升级已完成 |
| CloneSetProgressPaused | CloneSet is paused | 发布升级暂停中 |
| CloneSetProgressPartitionAvailable | CloneSet has been paused due to partition ready | 发布升级达到指定比例 |
进行中的 CloneSet
当执行以下任一操作时,CloneSet 将被标记为 Progressing 状态:
- 执行滚动升级操作。
- 升级过程中为最新版本 Revision 进行扩容。
- 升级过程中为旧版本 Revision 进行缩容。
- 新创建的 Pod 已就绪或可用(满足 MinReadySeconds 条件)。
此时,CloneSet控制器会在 .status.conditions 中添加以下状况条目:
type: Progressing
status: "True"
reason: CloneSetUpdated
可用的 CloneSet
Complete 状态分为两种子状态:
分组暂停状态:
当满足以下条件时,CloneSet 进入分组暂停状态:
- 指定 partition 比例的副本已更新至最新版本。
- 指定 partition 比例的副本均处于可用状态。
CloneSet 控制器会向 CloneSet 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressing
status: "True"
reason: ProgressPartitionAvailable
可用状态: 当以下条件发生时,Kruise 会将 CloneSet 变为可用状态:
- 所有副本均已更新至最新版本。
- 所有副本均处于可用状态。
- 无旧版本副本运行。
CloneSet 控制器会向 CloneSet 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressing
status: "True"
reason: CloneSetAvailable
Progressing 的状况将会持续保持 "True",直到触发新的升级部署操作。即使副本可用性发生变化,此状况值也不会改变。
失败的 CloneSet
当 CloneSet 无法成功部署最新 Revision 时,将进入 Failed 状态。常见原因包括:
- 资源配额不足
- 就绪探针失败
- 镜像拉取失败
- 权限不足
- LimitRanges 配置问题
- 应用运行时配置错误
通过配置 .spec.progressDeadlineSeconds 参数可检测此状况。超过截止时间后,CloneSet 控制器将向 .status.conditions 添加以下状况条目:
type: Progressing
status: "False"
reason: ProgressDeadlineExceeded
说明:
当用户暂停 CloneSet 部署时,控制器将停止进度检查。用户可在部署过程中安全地暂停和恢复操作,不会触发超时判定。
对失败 CloneSet 的操作
对于处于 Failed 状态的 CloneSet,可执行与 Complete 状态相同的管理操作,包括:
- 回滚到历史修订版本。
- 暂停部署过程以进行 Pod 模板的多项调整。
原地升级支持修改资源
FEATURE STATE: Kruise v1.8.0
如果你在安装或升级 Kruise 的时候启用了 InPlaceWorkloadVerticalScaling,
CloneSet 支持在原地升级过程中修改容器资源(CPU/Memory)。该功能允许用户直接更新以下字段而不触发 Pod 重建:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
#...
template:
spec:
containers:
- name: <container-name>
resources:
requests:
cpu: "2" # 可修改
memory: "2Gi" # 可修改
limits:
cpu: "4" # 可修改
memory: "4Gi" # 可修改
注意事项
-
该功能需在开启
InPlacePodVerticalScalingfeature-gate 的 Kubernetes 集群中才可以使用,请确保你的集群支持该功能。详情可查看Kubernetes 文档。 -
Cgroupv1 限制:
- 在 Cgroupv1 环境中,禁止同时修改镜像和资源字段(如同时更新镜像和 CPU 配额)。需分步操作:
- 先完成资源修改的原地升级
- 再触发镜像更新的原地升级
- 详细说明参考社区 Issue #127356
- 资源类型限制:
- 仅支持修改
requests和limits中的cpu/memory字段 - 其他资源类型(如 GPU)会触发 Pod 重建
- 修改资源时不能改变 Pod Qos,若 Pod Qos 改变会触发 Pod 重建
原地升级自动预热
FEATURE STATE: Kruise v0.9.0
如果你在安装或升级 Kruise 的时候启用了 PreDownloadImageForInPlaceUpdate feature-gate,
CloneSet 控制器会自动在所有旧版本 pod 所在 node 节点上预热你正在灰度发布的新版本镜像。 这对于应用发布加速很有帮助。
默认情况下 CloneSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像。
如果需要调整,你可以通过 apps.kruise.io/image-predownload-parallelism annotation 来设置并发度。
另外从 Kruise v1.1.0 开始,你可以使用 apps.kruise.io/image-predownload-min-updated-ready-pods 来控制在少量新版本 Pod 已经升级成功之后再执行镜像预热。它的值可能是绝对值数字或是百分比。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "10"
apps.kruise.io/image-predownload-min-updated-ready-pods: "3"
注意,为了避免大部分不必要的镜像拉取,目前只针对 replicas > 3 的 CloneSet 做自动预热。
生命周期钩子
每个 CloneSet 管理的 Pod 会有明确所处的状态,在 Pod label 中的 lifecycle.apps.kruise.io/state 标记:
- Normal:正常状态
- PreparingUpdate:准备原地升级
- Updating:原地升级中
- Updated:原地升级完成
- PreparingDelete:准备删除
而生命周期钩子,则是通过在上述状态流转中卡点,来实现原地升级前后、删除前的自定义操作(比如开关流量、告警等)。
type LifecycleStateType string
// Lifecycle contains the hooks for Pod lifecycle.
type Lifecycle struct
// PreDelete is the hook before Pod to be deleted.
PreDelete *LifecycleHook `json:"preDelete,omitempty"`
// InPlaceUpdate is the hook before Pod to update and after Pod has been updated.
InPlaceUpdate *LifecycleHook `json:"inPlaceUpdate,omitempty"`
// PreNormal is the hook after Pod to be created and ready to be Normal.
PreNormal *LifecycleHook `json:"preNormal,omitempty"`
}
type LifecycleHook struct {
LabelsHandler map[string]string `json:"labelsHandler,omitempty"`
FinalizersHandler []string `json:"finalizersHandler,omitempty"`
/********************** FEATURE STATE: 1.2.0 ************************/
// MarkPodNotReady = true means:
//- Pod will be set to 'NotReady' at preparingDelete/preparingUpdate state.
// - Pod will be restored to 'Ready' at Updated state if it was set to 'NotReady' at preparingUpdate state.
// Currently, MarkPodNotReady only takes effect on InPlaceUpdate & PreDelete hook.
// Default to false.
MarkPodNotReady bool `json:"markPodNotReady,omitempty"`
/*********************************************************************/
}
示例:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# 通过 finalizer 定义 hook
lifecycle:
preNormal:
finalizersHandler:
- example.io/unready-blocker
preDelete:
finalizersHandler:
- example.io/unready-blocker
inPlaceUpdate:
finalizersHandler:
- example.io/unready-blocker
# 或者也可以通过 label 定义
# lifecycle:
# inPlaceUpdate:
# labelsHandler:
# example.io/block-unready: "true"
升级/删除 Pod 前将其置为 NotReady
FEATURE STATE: Kruise v1.2.0
lifecycle:
preDelete:
markPodNotReady: true
finalizersHandler:
- example.io/unready-blocker
inPlaceUpdate:
markPodNotReady: true
finalizersHandler:
- example.io/unready-blocker
- 如果设置
preDelete.markPodNotReady=true:- Kruise 将会在 Pod 进入
PreparingDelete状态时,将KruisePodReady这个 Pod Condition 设置为False, Pod 将变为 NotReady。
- Kruise 将会在 Pod 进入
- 如果设置
inPlaceUpdate.markPodNotReady=true:- Kruise 将会在 Pod 进入
PreparingUpdate状态时,将KruisePodReady这个 Pod Condition 设置为False, Pod 将变为 NotReady。 - Kruise 将会尝试将
KruisePodReady这个 Pod Condition 设置回True。
- Kruise 将会在 Pod 进入
用户可以利用这一特性,在容器真正被停止之前将 Pod 上的流量先行排除,防止流量损失。
注意: 该特性仅在 Pod 被注入 KruisePodReady 这个 ReadinessGate 时生效。
流转示意
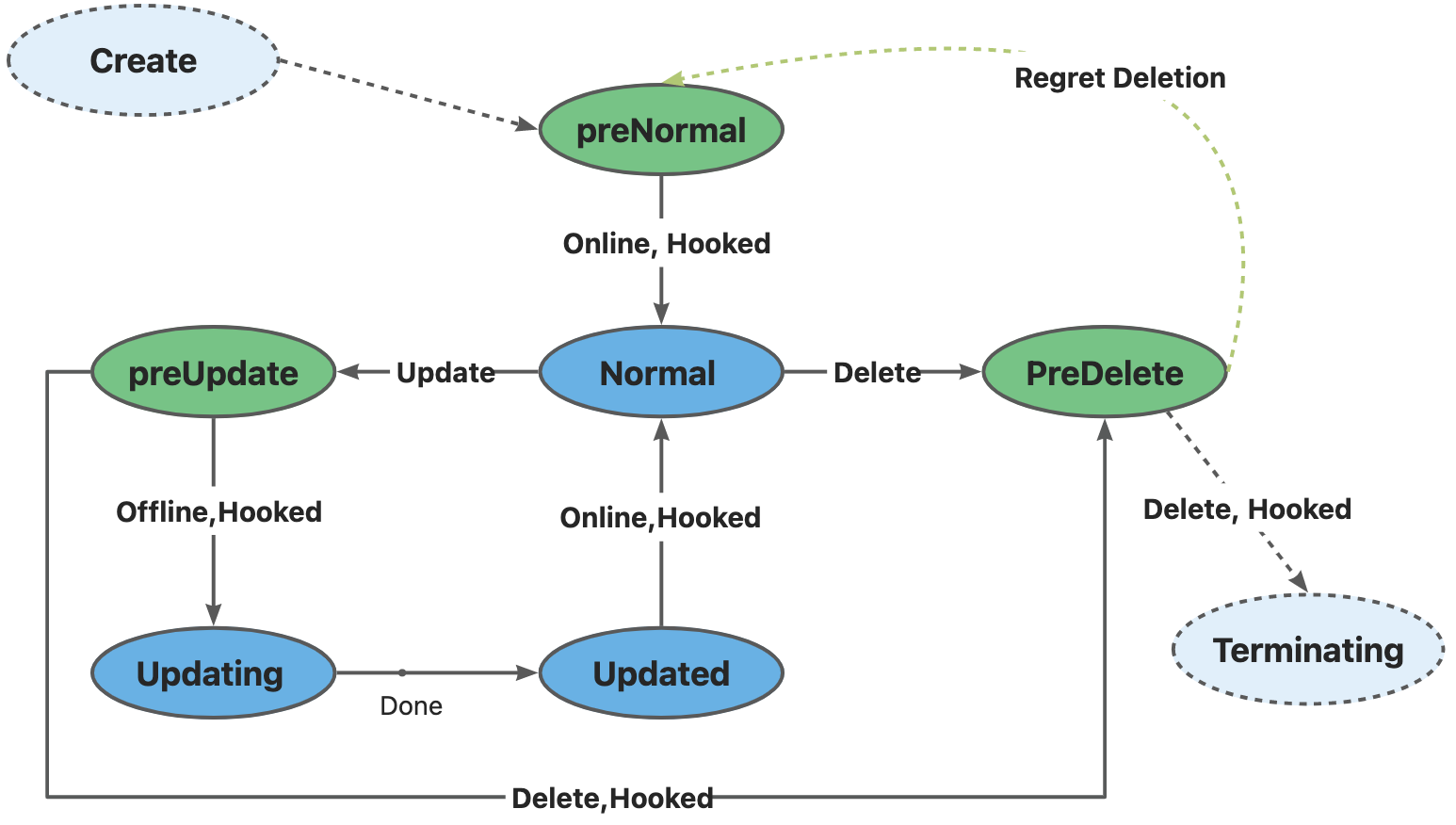
- 当 CloneSet 创建一个 Pod(包括正常扩容和重建升级)时:
- 如果 Pod 满足了
PreNormalhook 的定义,才会被认为是Available,并且才会进入Normal状态; - 这对于一些 Pod 创建时的后置检查很有用,比如你可以检查Pod是否已经挂载到SLB后端,从而避免滚动升级时,旧实例销毁后,新实例挂载失败导致的流量损失;
- 如果 Pod 满足了
- 当 CloneSet 删除一个 Pod(包括正常缩容和重建升级)时:
- 如果没有定义 lifecycle hook 或者 Pod 不符合 preDelete 条件,则直接删除
- 否则,先只将 Pod 状态改为
PreparingDelete。等用户 controller 完成任务去掉 label/finalizer、Pod 不符合 preDelete 条件后,kruise 才执行 Pod 删除 - 注意:
PreparingDelete状态的 Pod 处于删除阶段,不会被升级
- 当 CloneSet 原地升级一个 Pod 时:
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合 inPlaceUpdate 条件,则将 Pod 状态改为
PreparingUpdate - 等用户 controller 完成任务去掉 label/finalizer、Pod 不符合 inPlaceUpdate 条件后,kruise 将 Pod 状态改为
Updating并开始升级 - 升级完成后,如果定义了 lifecycle hook 且 Pod 不符合 inPlaceUpdate 条件,将 Pod 状态改为
Updated - 等用户 controller 完成任务加上 label/finalizer、Pod 符合 inPlaceUpdate 条件后,kruise 将 Pod 状态改为
Normal并判断为升级成功
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合 inPlaceUpdate 条件,则将 Pod 状态改为
关于从 PreparingDelete 回到 Normal 状态,从设计上是支持的(通过撤销指定删除),但我们一般不建议这种用法。由于 PreparingDelete 状态的 Pod 不会被升级,当回到 Normal 状态后可能立即再进入发布阶段,对于用户处理 hook 是一个难题。
用户 controller 逻辑示例
按上述例子,可以定义:
example.io/unready-blockerfinalizer 作为 hook
在 CloneSet template 模板里带上这个字段:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
lifecycle:
preNormal:
finalizersHandler:
- example.io/unready-blocker
preDelete:
finalizersHandler:
- example.io/unready-blocker
inPlaceUpdate:
finalizersHandler:
- example.io/unready-blocker
template:
# ...
而后用户 controller 的逻辑如下:
- 对于刚创建出来的 Pod,其会处于
PreparingNormal状态,当检查该 Pod 满足Available的标准后,将example.io/unready-blocker添加到 Pod 上, Pod 会转入Normal的可用状态。 - 对于
PreparingDelete和PreparingUpdate状态的 Pod,切走流量,并去除example.io/unready-blockerfinalizer - 对于
Updated状态的 Pod,接入流量,并打上example.io/unready-blockerfinalizer
扩缩容与 PreparingDelete
FEATURE STATE: Kruise v1.3.0
默认情况下,CloneSet 将处于 PreparingDelete 状态的 Pod 视为正常,意味着这些 Pod 仍然被计算在 replicas 数量中。
在这种情况下:
- 如果你将
replicas从N改为N-1,当一个要删除的 Pod 还在PreparingDelete状态中时,你重新将replicas改为N,CloneSet 会将这个 Pod 重新置为Normal状态。 - 如果你将
replicas从N改为N-1的同时在podsToDelete中设置了一个 Pod,当这个 Pod 还在PreparingDelete状态中时,你重新将replicas改为N,CloneSet 会等到这个 Pod 真正进入 terminating 之后再扩容一个 Pod 出来。 - 如果你在不改变
replicas的时候指定删除一个 Pod,当这个 Pod 还在PreparingDelete状态中时,CloneSet 会等到这个 Pod 真正进入 terminating 之后再扩容一个 Pod 出来。
从 Kruise v1.3.0 版本开始,你可以在 CloneSet 中设置一个 apps.kruise.io/cloneset-scaling-exclude-preparing-delete: "true" 标签,它标志着这个 CloneSet 不会将 PreparingDelete 状态的 Pod 计算在 replicas 数量中。
在这种情况下:
- 如果你将
replicas从N改为N-1,当一个要删除的 Pod 还在PreparingDelete状态中时,你重新将replicas改为N,CloneSet 会将这个 Pod 重新置为Normal状态。 - 如果你将
replicas从N改为N-1的同时在podsToDelete中设置了一个 Pod,当这个 Pod 还在PreparingDelete状态中时,你重新将replicas改为N,CloneSet 会立即创建一个新 Pod。 - 如果你在不改变
replicas的时候指定删除一个 Pod,当这个 Pod 还在PreparingDelete状态中时,CloneSet 会立即创建一个新 Pod。
性能优化
FEATURE STATE: Kruise v1.4.0
当前,无论是 Pod 的状态变化还是 Metadata 变化,Pod Update 事件都会触发 CloneSet reconcile 逻辑。CloneSet Reconcile 默认配置了三个 worker,对于集群规模较小的场景,这种情况并不会造成问题。
但对于集群规模较大或 Pod Update 事件较多的情况,这些无效的 reconcile 将会阻塞真正的 CloneSet reconcile,进而导致 CloneSet 的滚动升级等变更延迟。 为了解决这个问题,可以打开 feature-gate CloneSetEventHandlerOptimization 来减少一些不必要的 reconcile 入队。