OpenKruise 0.8.0, A Powerful Tool for Sidecar Container Management

OpenKruise 是阿里云开源的云原生应用自动化管理套件,也是当前托管在 Cloud Native Computing Foundation (CNCF) 下的Sandbox项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,是阿里内部生产环境大规模应用的基于Kubernetes之上的标准扩展组件,也是紧贴上游社区标准、适应互联网规模化场景的技术理念与最佳实践。
OpenKruise在2021.3.4发布了最新的v0.8.0版本,其中增强了SidecarSet的能力,特别是对日志管理类Sidecar有了更加完善的支持。
背景
Sidecar是云原生中一种非常重要的容器设计模式,它将辅助能力从主容器中剥离出来成为单独的sidecar容器。在微服务架构中,通常也使用sidecar模式将微服务中的配置管理、服务发现、路由、熔断等通用能力从主程序中剥离出来,从而极大降低了微服务架构中的复杂性。随着Service Mesh的逐步风靡,sidecar模式也日益深入人心,在阿里巴巴集团内部也大量使用sidecar模式来管理诸如运维、安全、消息中间件等通用组件。
在Kubernetes集群中,Pod不仅可以实现主容器与sidecar容器的构建,同时提供了许多功能强大的workload(例如:deployment、statefulset)来对Pod进行管理、升级。但是随着kubernetes集群上的业务日益增多,sidecar容器的种类与规模也随之日益庞大,对线上sidecar容器的管理和升级成为了愈发繁杂的工作:
- 业务Pod里面包含了运维、安全、代理等多个sidecar容器,业务线同学不仅要完成自身主容器的配置,而且还需要熟悉这些sidecar容器的配置,这不仅增加了业务同学的工作量,同时也无形增加了sidecar容器配置的风险。
- sidecar容器的升级需要连同业务主容器一起重启(deployment、statefulset等workload基于Pod销毁、重建的模式,来实现Pod的滚动升级),推动和升级支撑着线上数百款业务的sidecar容器,必然存在着极大的业务阻力。
- 作为sidecar容器的提供者对线上诸多各种配置以及版本的sidecar容器没有直接有效的升级手段,这对sidecar容器的管理意味着极大的潜在风险。
阿里巴巴集团内部拥有着百万级的容器数量连同上面承载的上千个业务,因此,sidecar容器的管理与升级也就成为了亟待完善的主题。因此,我们总结了内部许多sidecar容器的通用化需求,并将其沉淀到OpenKruise上面,最终抽象为SidecarSet作为管理和升级种类繁多sidecar容器的利器。
OpenKruise SidecarSet
SidecarSet是OpenKruise中针对sidecar抽象出来的概念,负责注入和升级kubernetes集群中的sidecar容器,是OpenKruise的核心workload之一。它提供了非常丰富的功能,用户使用SidecarSet可以非常方便实现sidecar容器的管理。主要特性如下:
- 配置单独管理:为每一个sidecar容器配置单独的SidecarSet配置,方便管理
- 自动注入:在新建、扩容、重建pod的场景中,实现sidecar容器的自动注入
- 原地升级:支持不重建pod的方式完成sidecar容器的原地升级,不影响业务主容器,并包含丰富的灰度发布策略
注意:针对Pod中包含多个容器的模式,其中对外提供主要业务逻辑能力的容器称之为 主容器,其它一些如日志采集、安全、代理等辅助能力的容器称之为 Sidecar容器。例如:一个对外提供web能力的pod,nginx容器提供主要的web server能力即为 主容器,logtail容器负责采集、上报nginx日志即为 Sidecar容器。本文中的SidecarSet资源抽象也是为解决 Sidecar容器 的一些问题。
Sidecar logging architectures
应用日志可以让你了解应用内部的运行状况,日志对调试问题和监控集群活动非常有用。应用容器化后,最简单且最广泛采用的日志记录方式就是写入标准输出和标准错误。
但是,在当前分布式系统、大规模集群的时代下,上述方案还不足以达到生产环境的标准。首先,对于分布式系统而言,日志都是分散在单个容器里面,没有一个统一汇总的地方。其次,如果发生容器崩溃、Pod被驱逐等场景,会出现日志丢失的情况。因此,需要一种更加可靠,独立于容器生命周期的日志解决方案。
Sidecar logging architectures 是将logging agent放到一个独立的sidecar容器中,通过共享日志目录的方式,实现容器日志的采集,然后存储到日志平台的后端存储。
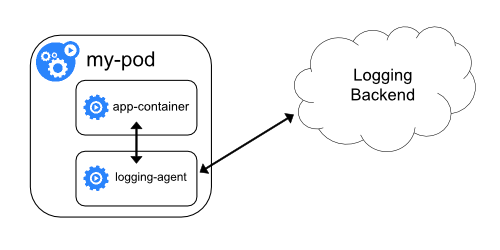
阿里巴巴以及蚂蚁集团内部同样也是基于这种架构实现了容器的日志采集,下面我将介绍OpenKruise SidecarSet如何助力 Sidecar日志架构在kubernetes集群中的大规模落地实践。
自动注入
OpenKruise SidecarSet基于kubernetes AdmissionWebhook机制实现了sidecar容器的自动注入,因此只要将sidecar配置到SidecarSet中,不管用户用 CloneSet、Deployment、StatefulSet 等任何方式部署,扩出来的 Pod 中都会注入定义好的 sidecar 容器。
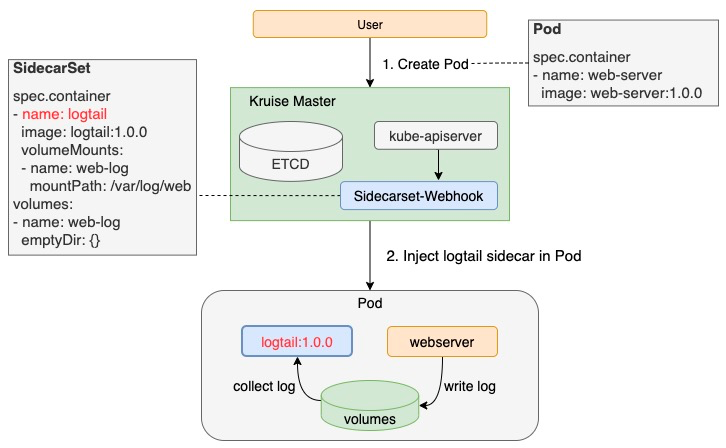
Sidecar容器的所有者只需要配置自身的SidecarSet,就可以在业务无感知的情况下完成sidecar容器的注入,这种方式极大的降低了sidecar容器使用的门槛,也方便了sidecar所有者的管理工作。为了满足sidecar注入的多种场景,SidecarSet除containers之外还扩展了如下字段:
# sidecarset.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: test-sidecarset
spec:
# 通过selector选择pod
selector:
matchLabels:
app: web-server
# 指定 namespace 生效
namespace: ns-1
# container definition
containers:
- name: logtail
image: logtail:1.0.0
# 共享指定卷
volumeMounts:
- name: web-log
mountPath: /var/log/web
# 共享所有卷
shareVolumePolicy:
type: disabled
# 环境变量共享
transferEnv:
- sourceContainerName: web-server
# TZ代表时区,例如:web-server容器中存在环境变量 TZ=Asia/Shanghai
envName: TZ
volumes:
- name: web-log
emptyDir: {}
- Pod选择器
- 支持selector来选择要注入的Pod,如示例中将选择labels[app] = web-server的pod,将logtail容器注入进去,也可以在所有的pod中添加一个labels[inject/logtail] = true的方式,来实现全局性的sidecar注入。
- namespace:sidecarSet默认是全局生效的,如果只想对某一个namespace生效,则配置该参数
- 数据卷共享:
- 共享指定卷:通过volumeMounts和volumes可以完成与主容器的特定卷的共享,如示例中通过共享web-log volume来达到日志采集的效果
- 共享所有卷:通过 shareVolumePolicy = enabled | disabled 来控制是否挂载pod主容器的所有卷卷,常用于日志收集等 sidecar,配置为 enabled 后会把应用容器中所有挂载点注入 sidecar 同一路经下(sidecar中本身就有声明的数据卷和挂载点除外)
- 环境变量共享 可以通过 transferEnv 从其它容器中获取环境变量,会把名为 sourceContainerName 容器中名为 envName 的环境变量拷贝到本sidecar容器,如示例中 日志sidecar容器共享了主容器的时区TZ,这在海外环境中尤其常见
注意:kubernetes社区对于已经创建的Pod不允许修改container数量,所以上述注入能力只能发生在Pod创建阶段,对于已经创建的Pod需要通过重建的方式来注入。
原地升级
SidecarSet不仅实现sidecar容器的注入,而且复用了OpenKruise中原地升级的特性,实现了在不重启Pod和主容器的前提下单独升级sidecar容器的能力。由于这种升级方式基本上能做到业务方无感知的程度,所以sidecar容器的升级已不再是上下交困的难题,从而极大解放了sidecar的所有者,提升了sidecar版本迭代的速度。
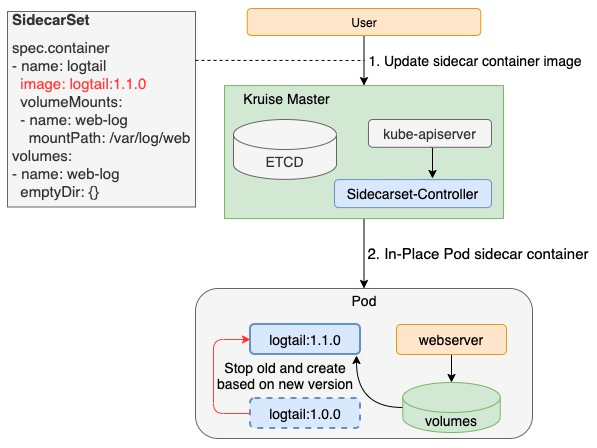
注意:kubernetes社区对于已经创建的Pod只允许修改 container.image 字段,因此对于sidecar容器的修改包含除 container.image 的其它字段,则需要通过Pod重建的方式,不能直接原地升级。
为了满足一些复杂的sidecar升级场景,SidecarSet除了原地升级以外,还提供了非常丰富的灰度发布策略。
灰度发布
灰度发布应该算是日常发布中最常见的一种手段,它能够比较平滑的完成sidecar容器的发布,尤其是在大规模集群的场景下,强烈建议使用这种方式。下面是 首批暂停,后续基于 最大不可用 滚动发布 的例子,假设一个有1000个pod需要发布:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
partition: 980
maxUnavailable: 10%
上述配置首先发布(1000 - 980)= 20 个pod之后就会暂停发布,业务可以观察一段时间发现 sidecar 容器正常后,调整重新 update SidecarSet 配置:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
maxUnavailable: 10%
这样调整后,对于余下的 980 个pod,将会按照最大不可用的数量(10% * 1000 = 100)的顺序进行发布,直到所有的pod都发布完成。
Partition 的语义是 保留旧版本 Pod 的数量或百分比,默认为 0。这里的 partition 不表示任何 order 序号。如果在发布过程中设置了 partition:
- 如果是数字,控制器会将 (replicas - partition) 数量的 Pod 更新到最新版本。
- 如果是百分比,控制器会将 (replicas * (100% - partition)) 数量的 Pod 更新到最新版本。
MaxUnavailable 是发布过程中保证的,同一时间下最大不可用的 Pod 数量,默认值为 1。用户可以将其设置为绝对值或百分比(百分比会被控制器按照selected pod做基数来计算出一个背后的绝对值)。
注意:maxUnavailable 和 partition 两个值是没有必然关联。举例:
- 当 {matched pod}=100,partition=50,maxUnavailable=10,控制器会发布 50 个 Pod 到新版本,但是发布窗口为 10,即同一时间只会发布 10 个 Pod,每发布好一个 Pod 才会再找一个发布,直到 50 个发布完成。
- 当 {matched pod}=100,partition=80,maxUnavailable=30,控制器会发布 20 个 Pod 到新版本,因为满足 maxUnavailable 数量,所以这 20 个 Pod 会同时发布。
金丝雀发布
对于有金丝雀发布需求的业务,可以通过strategy.selector来实现。方式:对于需要率先金丝雀灰度的pod打上固定的labels[canary.release] = true,再通过strategy.selector.matchLabels来选中该pod
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
canary.release: "true"
maxUnavailable: 10%
上述配置只会发布打上金丝雀labels的容器,在完成金丝雀验证之后,通过将 updateStrategy.selector 配置去掉,就会继续通过 最大不可用 来滚动发布。
打散发布
SidecarSet对于pod的升级顺序,默认按照如下规则:
- 对升级的pod集合,保证多次升级的顺序一致
- 选择优先顺序是(越小优先级越高): unscheduled < scheduled, pending < unknown < running, not-ready < ready, newer pods < older pods
除了上述默认发布顺序之外,scatter打散策略允许用户 自定义将符合某些标签的 Pod 打散 到整个发布过程中。比如,对于像 logtail 这种全局性的 sidecar container,一个集群当中很可能注入了几十个业务pod,因此可以使用基于 应用名 的方式来打散logtail的方式进行发布,实现 不同应用间打散灰度发布 的效果,并且这种方式可以同 最大不可用 一起使用。
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
# 配置pod labels,假设所有的pod都包含labels[app_name]
scatterStrategy:
- key: app_name
value: nginx
- key: app_name
value: web-server
- key: app_name
value: api-gateway
maxUnavailable: 10%
注意:当前版本必须要列举所有的应用名称,我们将在下个版本支持 只配置label key 的智能打散方式。
总结
本次 OpenKruise v0.8.0 版本的升级,SidecarSet特性主要是完善了 日志管理类Sidecar 场景的能力,后续我们在持续深耕SidecarSet稳定性、性能的同时,也将覆盖更多的场景,比如下一个版本将会增加针对 Service Mesh场景 的支持。同时,我们也欢迎更多的同学参与到 OpenKruise 社区来,共同建设一个场景更加丰富、完善的 K8s 应用管理、交付扩展能力,能够面向更加规模化、复杂化、极致性能的场景。

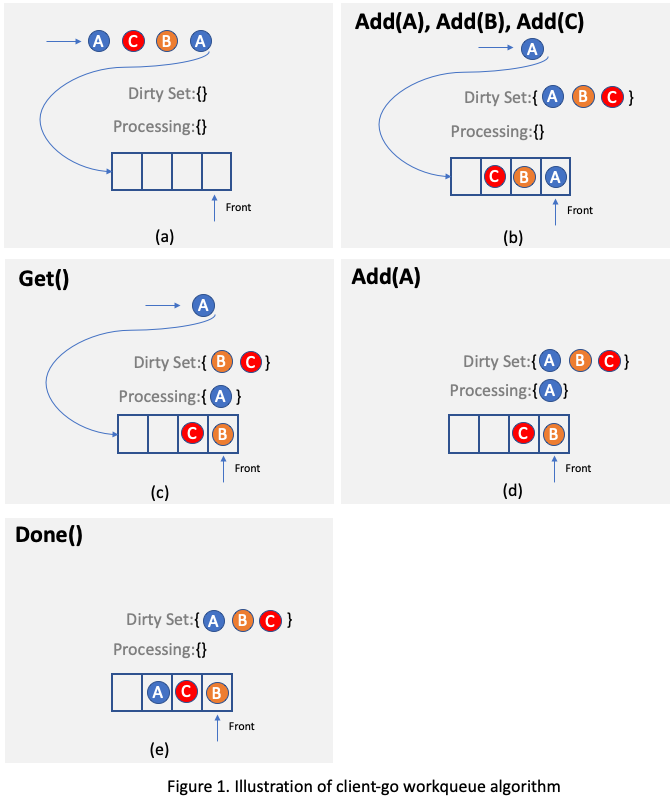
 .... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the
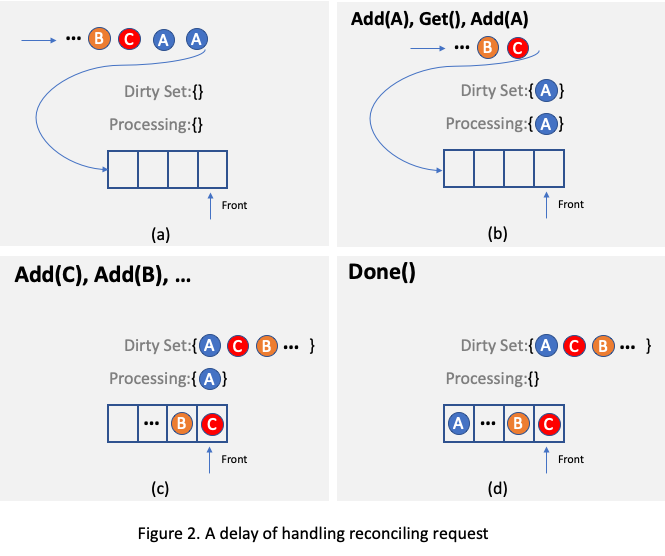
.... For example, as illustrated in
Figure 2, assuming there is only one reconciling thread and two requests targeting the same object A arrive, one of
them will be processed and object A will be added to the 