基于HPA的极致弹性调度最佳实践
自 0.10.0 版本开始,OpenKruise 提出了一种基于旁路(by-pass)架构的多域管理组件 --- WorkloadSpread。它允许用户将 Workload 的副本在不同节点、不同机房、甚至不同云厂商中进行多域化编排,并允许用户对不同域的副本进行差异化配置。WorkloadSpread 可以以无侵入的方式,赋予存量的/增量的 Workload 多域打散、弹性调度、精细化管理的能力。
接下来,本文将基于 WorkloadSpread 的特性,以一个简单的 Web 应用为例,结合 KEDA、Prometheus、阿里云弹性实例等,来帮助用户构建一个基于自定义指标的自动化极致弹性调度方案。
方案
方案架构
本文将会以一个 PHP 实现的 Hello-World Web 程序来模拟用户应用,整体方案架构如下:
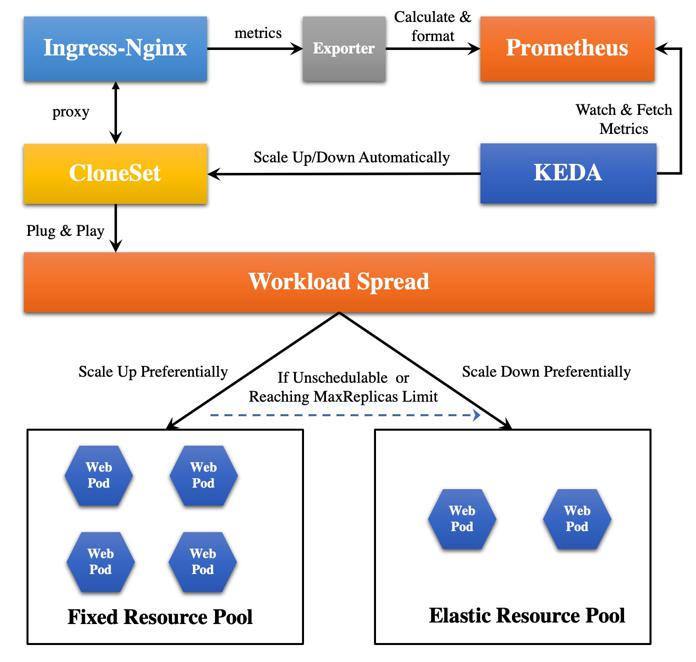
特别说明:
-
在该方案中,HPA 通过 KEDA 进行管理。KEDA 是一个基于 Kubernetes HPA 实现的加强版自动化伸缩组件,相较于原生的 HPA 组件,它适配了更丰富的自定义指标度量接口。
-
在该方案中,Prometheus 采集 Ingress-Nginx 而不是 Web Pod 的指标数据,其实是一个取巧的操作。这是因为,业务接入 Prometheus 需要进行一定的业务改造,较为繁琐,而 Nginx 有暴露链接数目等指标的模块,并且有官方开源的 Exporter。最重要的是,进入 Web Pod 的流量一定要经过 Ingress-Nginx,所以本文直接以 Ingress-Nginx 的指标作为标准,对接 KEDA 组件实现自动化扩缩容。
-
由于 WorkloadSpread 需要 1.21 及以上的 Kubernetes 版本才能支持 Deployment(因为需要 APIServer PodDeletionCost 特性,该特性在 1.21 开始支持,默认关闭,在 1.22 版本开始默认开启)。然而,本文采用的 ACK Kubernetes 集群目前最高支持到 1.20 版本,因此,本文以 CloneSet 为例进行演示(CloneSet 在 OpenKruise 0.9.0 开始支持 PodDeletionCost 特性)。
方案目标
该方案将基于一段时间窗口内 Nginx 所处理连接数作为指标:
- 当流量高峰到来,该指标超过了指标(这里的指标 可以根据实际需要自行进行定义),则认为需要进行自动扩容;
- 当扩缩时,优先将 Pod 扩容至长期持有的固定资源池,当固定资源池的资源不足或 Pod 数量达到设定阈值时,则自动弹性扩容到弹性资源池;
- 当流量高峰过去,关注的指标低于了阈值,则认为需要进行自动缩容;
- 当缩容时,优先缩容弹性资源池中的副本;
环境配置
本文将基于阿里云 ACK 集群进行演示,其中共包含 3 个ECS节点,模拟固定资源池,1个 Virtual-Kubelet 节点,用于申请和管理弹性实例,模拟弹性资源池:
$ k get node
NAME STATUS ROLES AGE VERSION
us-west-1.192.168.0.47 Ready <none> 153d v1.20.11-aliyun.1
us-west-1.192.168.0.48 Ready <none> 153d v1.20.11-aliyun.1
us-west-1.192.168.0.49 Ready <none> 153d v1.20.11-aliyun.1
virtual-kubelet-us-west-1a Ready agent 19d v1.20.11-aliyun.1
安装 OpenKruise
更多安装细节请参考官方安装文档,这里建议安装最新版本。
安装 KEDA
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm repo update
$ kubectl create namespace keda
$ helm install keda kedacore/keda --namespace keda
安装 Ingress-Nginx-Controller
首先,创建相应的 Namespace:
$ kubectl create ns ingress-nginx
因为 Exporter 需要能够访问 Nginx Status 接口,以便获取连接数等基础数据。因此,在安装该 Controller 之前,我们需要先下发一个 Nginx Configuration 相关的 ConfigMap,目的是把默认的一些配置进行覆盖,将 Status 接口暴露出来,供 Nginx-Prometheus-Exporter 消费:
apiVersion: v1
data:
allow-snippet-annotations: "true"
http-snippet: |
server {
listen 8080;
server_name _ ;
location /stub_status {
stub_status on;
}
location / {
return 404;
}
}
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: ingress-nginx
meta.helm.sh/release-namespace: ingress-nginx
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/version: 1.1.0
helm.sh/chart: ingress-nginx-4.0.13
name: ingress-nginx-controller
namespace: ingress-nginx
准备一个 values.yaml 文件,以便在部署 Ingress-Nginx-Controller Deployment 时将 8080 端口暴露出来:
# values.yaml
controller:
containerPort:
http: 80
https: 443
status: 8080
安装部署 Ingress-Nginx-Controller:
$ helm upgrade --install ingress-nginx ingress-nginx --repo https://kubernetes.github.io/ingress-nginx --namespace ingress-nginx --values values.yaml
因为 Ingress-Nginx-Controller 80 和 443 端口是对外提供服务,使用的是 LoadBalancer 类型的Service,而 8080 端口只是为了暴露给 Exporter,而 Exporter 和 Prometheus 完全可以部署在集群内部,只对内提供服务,因此此处应使用 ClusterIP 类型 Service 来对接 Nginx 8080 端口,使其只在集群内部暴露:
kind: Service
apiVersion: v1
metadata:
name: ingress-nginx-controller-8080
namespace: ingress-nginx
spec:
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: ClusterIP
ports:
- name: myapp
port: 8080
targetPort: status
安装 Nginx-Prometheus-Exporter
nginx 暴露出的 Status 数据并未遵循 Prometheus 的格式标准,因此需要一个 Exporter 组件进行数据采集和格式转换,此处采用 Nginx 官方提供的 Nginx-Prometheus-Exporter:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-nginx-exporter
namespace: ingress-nginx
labels:
app: ingress-nginx-exporter
spec:
selector:
matchLabels:
app: ingress-nginx-exporter
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: ingress-nginx-exporter
spec:
containers:
- image: nginx/nginx-prometheus-exporter:0.10
imagePullPolicy: IfNotPresent
args:
- -nginx.scrape-uri=http://ingress-nginx-controller-8080.ingress-nginx.svc.cluster.local:8080/stub_status
name: main
ports:
- name: http
containerPort: 9113
protocol: TCP
resources:
limits:
cpu: "200m"
memory: "256Mi"
安装 Prometheus-Operator
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm install [RELEASE] prometheus-community/kube-prometheus-stack --namespace prometheus --create-namespace
本文 [RELEASE] 设置为 kube-prometheus-stack-1640678515, 这串字符决定了后续的一些配置,如需改动,后续一些 yaml 文件中的一些配置也需改动。
Prometheus 安装完成后下发 ServiceMonitor, 来监控 Ingress-Nginx 暴露出的指标:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
release: kube-prometheus-stack-1640678515
name: ingress-nginx-monitor
namespace: ingress-nginx
spec:
selector:
matchLabels:
app: ingress-nginx-exporter
endpoints:
- interval: 10s
port: exporter
测试环境配置是否正确
上述环境安装配置完成后,我们需要先检查一下环境配置的正确性。
测试 Nginx Status 接口是否正常
首先,我们随便拉起一个带 shell 和 curl 等工具的 Pod,例如:
apiVersion: v1
kind: Pod
metadata:
name: centos
namespace: ingress-nginx
spec:
containers:
- name: main
image: centos:latest
command: ["/bin/sh", "-c", "sleep 100000000"]
resources:
limits:
memory: "512Mi"
cpu: "500m"
ports:
- containerPort: 8080
然后,登入该 Pod main 容器进行连接测试:
$ k exec busybox -n ingress-nginx -it -- /bin/sh
sh-4.4# curl -L http://ingress-nginx-controller-8080.ingress-nginx.svc.cluster.local:8080/stub_status
Active connections: 6
server accepts handled requests
12092 12092 23215
Reading: 0 Writing: 1 Waiting: 5
如执行上述 curl 后输出类似内容,则表示接口正常。
测试 Prometheus 数据采集是否正常
我们通过 Helm 安装 Prometheus-Operator 时,其实也已经将 Grafana 安装上了。因此,我们可以登入 Grafana 这个可视化工具,来查看我们想要的 Nginx 的指标有没有被采集到。 因为 Grafana 也部署在 ACK 集群,节点在远端,因此想要使用本地浏览器访问 Grafana,我们需要改动一下 Grafana Service Type,将其改为 LoadBalancer 类型,这样 ACK 会自动给 Grafana 分配一个外部地址。拿到这个外部地址,我们就可以使用本地浏览器访问 Grafana。 Grafana 初始账号密码可以从相应的 Secret 中解析得到:
user: admin
password: prom-operator
登入 Grafana 后,点击左侧导航栏中的 Explore ,在 Metrics browser 中可以看到 Prometheus 采集存储的指标列表,如果我们关注的指标存在,则表示采集成功。
弹性部署
完成上述环境准备就绪,并确认一切正常后,接下来便可以部署应用以及弹性组件。
应用部署
以 Hello-Web 应用为例,访问该应用会返回一个简单的 html 页面,内容类似如下:
Hello Web
Current Backend Server Info
Server Name: hello-web-57b767f456-bnw24
Server IP: 47.89.252.93
Server Port: 80
Current Client Request Info
Request Time Float: 1640766227.537
Client IP: 10.64.0.65
Client Port: 52230
User Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
Request Method: GET
Thank you for using PHP.
Request URI: /
使用 CloneSet 将其进行部署:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: hello-web
namespace: ingress-nginx
labels:
app: hello-web
spec:
replicas: 1
selector:
matchLabels:
app: hello-web
template:
metadata:
labels:
app: hello-web
spec:
containers:
- name: hello-web
image: zhangsean/hello-web
ports:
- containerPort: 80
resources:
requests:
cpu: "1"
memory: "256Mi"
limits:
cpu: "2"
memory: "512Mi"
---
kind: Service
apiVersion: v1
metadata:
name: hello-web
namespace: ingress-nginx
spec:
type: ClusterIP
selector:
app: hello-web
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-web
namespace: ingress-nginx
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: hello-web
port:
number: 80
ingressClassName: nginx
部署 WorkloadSpread
apiVersion: apps.kruise.io/v1alpha1
kind: WorkloadSpread
metadata:
name: workloadspread-sample
namespace: ingress-nginx
spec:
targetRef:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
name: ingress-nginx-controller
scheduleStrategy:
type: Adaptive
adaptive:
rescheduleCriticalSeconds: 2
subsets:
- name: fixed-resource-pool
requiredNodeSelectorTerm:
matchExpressions:
- key: type
operator: NotIn
values:
- virtual-kubelet
patch:
metadata:
labels:
resource-pool: fixed
- name: elastic-resource-pool
requiredNodeSelectorTerm:
matchExpressions:
- key: type
operator: In
values:
- virtual-kubelet
tolerations:
- effect: NoSchedule
key: virtual-kubelet.io/provider
operator: Exists
patch:
metadata:
labels:
resource-pool: elastic
上述 WorkloadSpread 共包含两个 Subset,分别对应固定资源池和弹性资源池。我们期望名为 hello-web 的 CloneSet 尽量地先将 Pod 往固定资源池去调度,当该资源池不可调度时,再往弹性资源池去调度。
WorkloadSpread 的大概原理是利用了 Kubernetes 的 Webhook 机制。当 APIServer 收到相应 Pod 的创建请求时,会调用 Kruise Webhook,将相应的 WorkloadSpread 的调度规则注入到 Pod。WorkloadSpread 在注入时采用的是追加机制,而不是替换机制。例如,假设 Pod 本身已经有了一些 requiredNodeSelectorTerm 或者 Tolerations 规则定义, WorkloadSpread 会在这些已有配置的基础上,把 Subset 中的调度规则 append 上去。
因此,我们建议:
- 将一些 共有的、不轻易改变 的调度规则写到 Workload,最好能保证不经过 WorkloadSpread 也能调度成功;
- 将 Subset 个性化的调度规则,配置到 WorkloadSpread Subset;
部署 ScaleObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ingress-nginx-scaledobject
namespace: ingress-nginx
spec:
maxReplicaCount: 10
minReplicaCount: 1
pollingInterval: 10
cooldownPeriod: 2
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 10
scaleTargetRef:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
name: hello-web
triggers:
- type: prometheus
metadata:
serverAddress: http://kube-prometheus-stack-1640-prometheus.prometheus:9090/
metricName: nginx_http_requests_total
query: sum(rate(nginx_http_requests_total{job="ingress-nginx-exporter"}[12s]))
threshold: '100'
效果展示
首先,检查一下配置是否都已经下发:

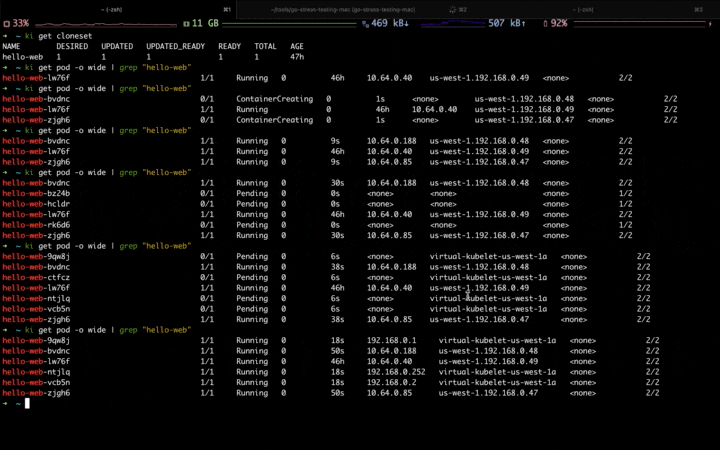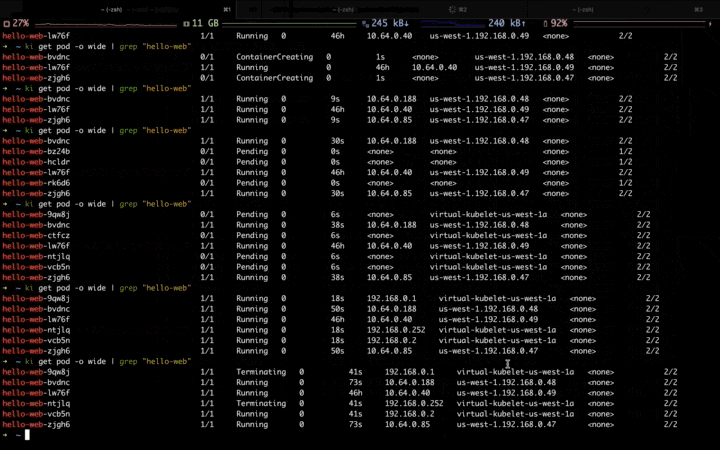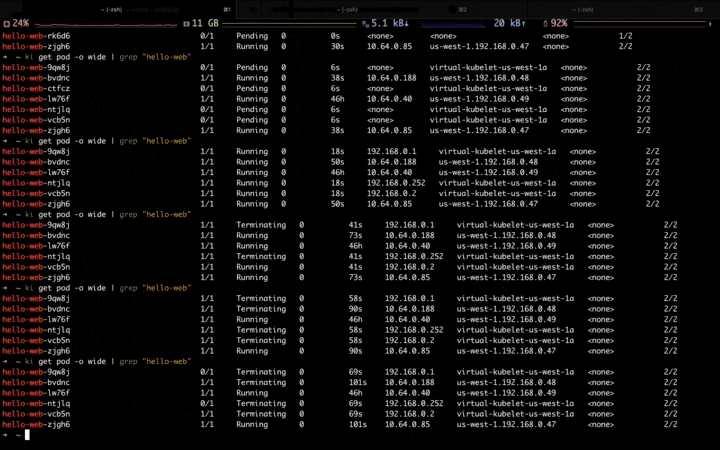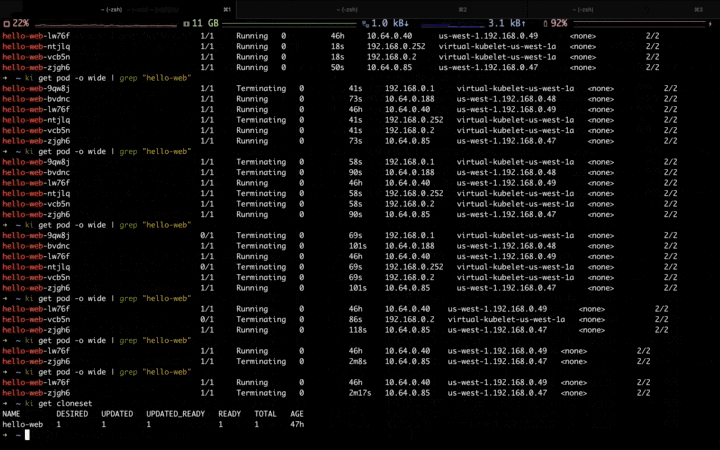
然后,使用 go-stress-testing 压测工具对上述应用进行压测。
当第一波流量到来,可以看到应用正在自动扩容,并且扩容到固定资源池:

当第二波流量高峰到来,固定资源池的资源逐渐不足,开始扩容到弹性资源池:
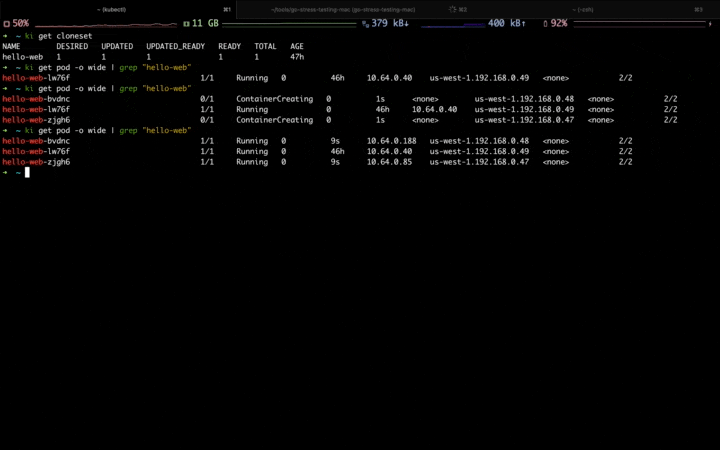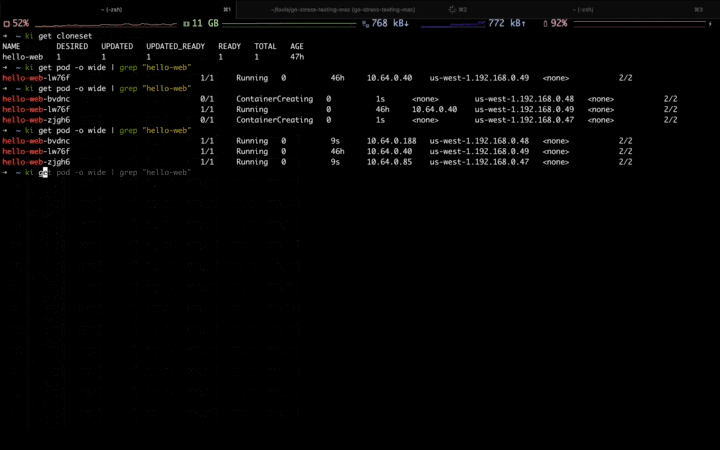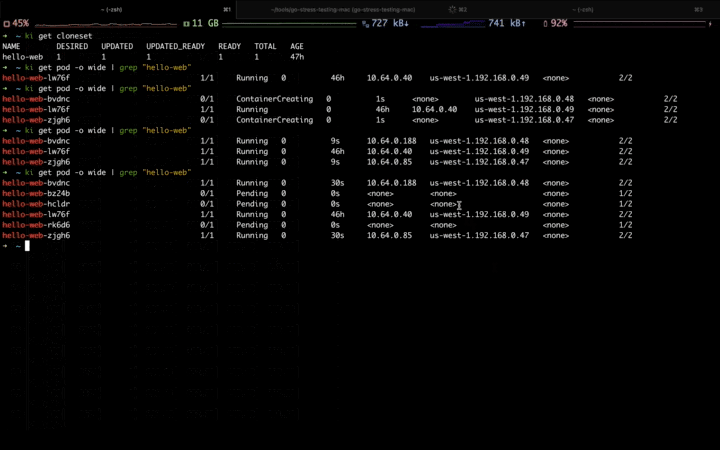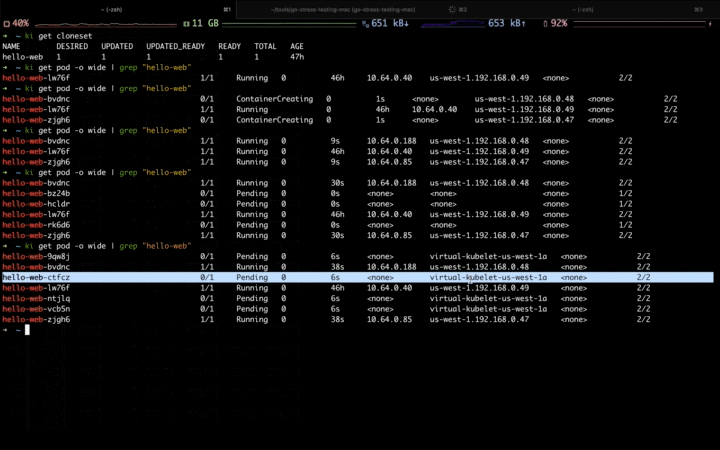
高峰流量过去,应用开始自动缩容,首先会缩掉弹性资源池中的副本,等弹性资源缩容完毕,再缩容固定资源池中的副本: